Python 中 UnicodeDecodeError: 'charmap' codec can't decode byte 错误
Python“UnicodeDecodeError: 'charmap' codec can't decode byte in position”发生在我们指定不正确的编码或在打开文件时未显式设置编码关键字参数时。
要解决错误,请指定正确的编码,例如 utf-8。
下面是错误如何发生的示例。
我有一个名为 example.txt 的文件,其中包含以下内容。
example.txt
𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
这是尝试解码 example.txt 内容的代码。
# ⛔️ UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 1: character maps to <undefined>
with open('example.txt', 'r', encoding='cp856') as f:
lines = f.readlines()
print(lines)
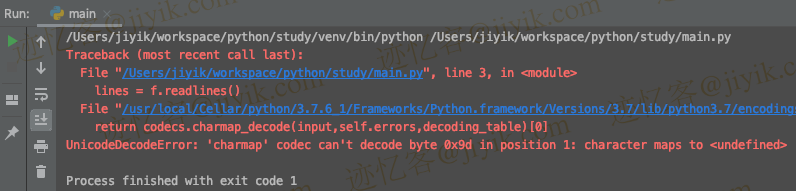
错误是因为 example.txt 文件没有使用指定的编码。
打开文件时指定正确的编码
如果我们知道文件使用的编码,请确保使用 encoding 关键字参数指定它。
否则,我们可以尝试的第一件事是将编码设置为 utf-8。
with open('example.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
# ✅ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
print(lines)
utf-8 编码能够在 Unicode 中编码超过一百万个有效字符代码点。
如果我们直接使用 open() 函数而不是使用 with 语句,则可以使用相同的方法。
my_file = open('example.txt', 'r', encoding='utf-8')
lines = my_file.readlines()
print(lines) # ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
我们可以在官方文档的此表中查看所有标准编码。
一些常见的编码是 ascii、latin-1 和 utf-32。
忽略无法解码的字符
如果错误仍然存在,我们可以将 errors 关键字参数设置为 ignore 以忽略无法解码的字符。
请注意,忽略无法解码的字符会导致数据丢失。
# 👇️ set errors to ignore
with open('example.txt', 'r', encoding='utf-8', errors='ignore') as f:
lines = f.readlines()
# ✅ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
print(lines)
使用设置为忽略的错误编码打开文件不会引发 UnicodeDecodeError。
with open('example.txt', 'r', encoding='cp856', errors='ignore') as f:
lines = f.readlines()
# ✅ ['\xadרט©ז\xadצ\xadץ»┘©×םן\n', 'hello world']
print(lines)
无法解码的字符将被忽略。
以二进制模式打开文件
如果我们不需要与文件内容进行交互,我们可以在不解码的情况下以二进制模式打开它。
with open('example.txt', 'rb') as f:
lines = f.readlines()
# ✅ [b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f\n', b'hello world']
print(lines)
我们以二进制模式打开文件(使用 rb - 读取二进制模式),因此行列表包含字节对象。
如果我们需要将文件上传到远程服务器并且不需要对其进行解码,则可以使用这种方法。
编码是将字符串转换为字节对象的过程,解码是将字节对象转换为字符串的过程。
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
尝试使用 cp437 编码
如果错误依旧,请尝试在打开文件时使用cp437编码。
with open('example.txt', 'r', encoding='cp437') as f:
lines = f.readlines()
# ✅ ['≡¥ÿêß╕å≡¥ûó≡¥ò»┘ñß╕₧╘ì╨¥╟Å\n', 'hello world']
print(lines)
代码页 437 编码是原始 IBM 个人计算机的字符集,包括所有可打印的 ASCII 字符以及一些重音字母。
如果仍然出现错误,请在调用 open() 函数时将 errors 关键字参数设置为 ignore。
with open('example.txt', 'r', encoding='cp437', errors='ignore') as f:
lines = f.readlines()
# ✅ ['≡¥ÿêß╕å≡¥ûó≡¥ò»┘ñß╕₧╘ì╨¥╟Å\n', 'hello world']
print(lines)
无法解码的字符将被忽略,这可能会导致数据丢失。
如果错误仍然存在,请尝试其他编码,例如 utf-16、utf-32、latin-1 等。
试图找到文件的编码
我们可以尝试使用 file 命令来弄清楚文件的编码是什么。
该命令在 macOS 和 Linux 上可用,但如果安装了 git 和 Git Bash,也可以在 Windows 上使用。
如果在 Windows 上,请确保在 Git Bash 中运行该命令。
在包含该文件的目录中打开 shell,然后运行以下命令。
file *
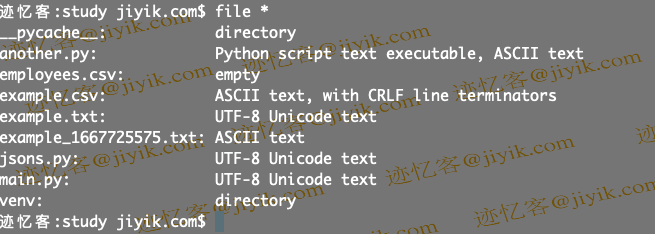
屏幕截图显示该文件使用 UTF-8 编码。
这是我们在打开文件时应指定的编码。
with open('example.txt', 'r', encoding='UTF-8') as f:
lines = f.readlines()
print(lines)
使用不同的编码会导致错误
下面是一个示例,展示了如何使用不同的编码将字符串编码为字节而不是用于解码字节对象的编码会导致错误。
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
my_binary_data = my_text.encode('utf-8')
# ⛔️ UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 1: character maps to <undefined>
my_text_again = my_binary_data.decode('cp856')
我们可以通过使用 utf-8 编码解码 bytes 对象来解决错误。
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
my_binary_data = my_text.encode('utf-8')
# 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f'
print(my_binary_data)
# ✅ specify correct encoding
my_text_again = my_binary_data.decode('utf-8')
print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
总结
Python“UnicodeDecodeError: 'charmap' codec can't decode byte in position”发生在我们指定不正确的编码或在打开文件时未显式设置编码关键字参数时。
要解决错误,请指定正确的编码,例如 utf-8。
相关文章
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串
在 Python Pandas 中使用 str.split 将字符串拆分为两个列表列
发布时间:2024/04/24 浏览次数:1124 分类:Python
-
本教程介绍如何使用 pandas str.split() 函数将字符串拆分为两个列表列。
在 Pandas 中将 Timedelta 转换为 Int
发布时间:2024/04/23 浏览次数:231 分类:Python
-
可以使用 Pandas 中的 dt 属性将 timedelta 转换为整数。
Python 中的 Pandas 插入方法
发布时间:2024/04/23 浏览次数:112 分类:Python
-
本教程介绍了如何在 Pandas DataFrame 中使用 insert 方法在 DataFrame 中插入一列。
使用 Python 将 Pandas DataFrame 保存为 HTML
发布时间:2024/04/21 浏览次数:106 分类:Python
-
本教程演示如何将 Pandas DataFrame 转换为 Python 中的 HTML 表格。
如何将 Python 字典转换为 Pandas DataFrame
发布时间:2024/04/20 浏览次数:73 分类:Python
-
本教程演示如何将 python 字典转换为 Pandas DataFrame,例如使用 Pandas DataFrame 构造函数或 from_dict 方法。
如何在 Pandas 中将 DataFrame 列转换为日期时间
发布时间:2024/04/20 浏览次数:101 分类:Python
-
本文介绍如何将 Pandas DataFrame 列转换为 Python 日期时间。

