在 Python 中检测和删除异常值
在数据集中,异常值是与数据集的其余部分异常不同的项目。 然而,这个定义为数据分析师提供了足够的空间来决定异常的阈值。
由于测量错误、执行错误、抽样问题、不正确的数据输入,甚至是自然变化,我们都会有异常值。 移除异常值很重要,因为它们的存在会增加错误、引入偏差并显着影响统计模型。
在本教程中,我们将讨论检测和删除数据集中异常值的方法。 我们将通过将我们的技术应用于著名的波士顿住房数据集(scikit-learn 库的一部分)来证明这一点。
本文的结构使得我们将探索一种检测异常值的方法,然后讨论如何使用该技术来删除异常值。
如果您希望按照教程进行操作,可以在浏览器中使用 Google Colab 进行操作。 就像打开一个新笔记本并编写代码一样简单。
这是开始使用 Google Colab 的分步指南。
设置环境并加载数据集
我们首先导入一些我们将要使用的库。
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
然后我们可以加载 Boston Housing 数据集。
bh_dataset = load_boston()
数据集包含一个 feature_names 属性,一个包含数据集中所有要素名称的数组。 数据属性包含所有数据。
我们将把两者分开,然后将它们组合起来创建一个 Pandas 数据框。
columns = bh_dataset.feature_names
df_boston = pd.DataFrame(bh_dataset.data)
df_boston.columns = columns
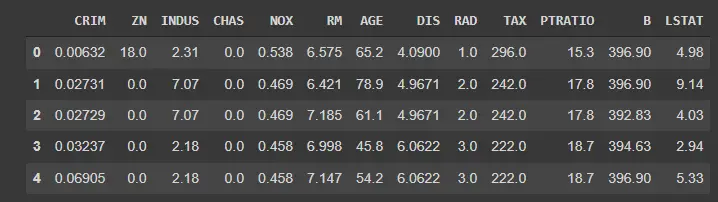
df_boston 现在包含整个数据集。 Pandas 允许我们使用 .head() 方法以一种干净直接的方式来预览我们的数据集。
调用如下所示的函数将显示数据集的预览(也如下所示)。
df_boston.head()
输出:
在 Python 中可视化数据集
生成箱形图以可视化数据集
箱形图,也称为盒须图,是一种简单有效的数据可视化方法,特别有助于查找异常值。 在 python 中,我们可以使用 seaborn 库生成数据集的箱线图。
import seaborn as sns
sns.boxplot(df_boston['DIS'])
上面代码的输出:
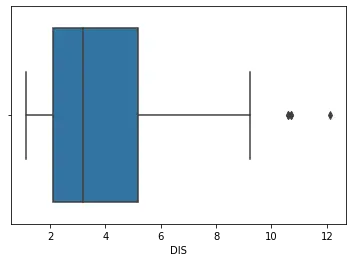
使用“DIS”索引数据集意味着将 DIS 列传递到箱形图函数中。 箱形图是在一维中生成的。
因此,它只需要一个变量作为输入。 可以更改变量以生成不同的箱线图。
在上图中,我们可以看到高于 10 的值是异常值。 我们现在将使用它作为该数据集中异常值的标准。
我们可以使用 np.where 选择数据集中符合此标准的条目,如下例所示。
import numpy as np
DIS_subset = df_boston['DIS']
print(np.where(DIS_subset > 10))
输出:

这些是包含数据点的数组索引,这些数据点是上述标准定义的异常值。 在文章的最后,我们将向您展示如何使用这些索引从数据集中删除异常值。
生成散点图以可视化数据集
当我们有一个单一维度的数据时,可以使用箱线图。 但是,如果我们有配对数据或我们正在分析的关系涉及两个变量,我们可以使用散点图。
Python 允许我们使用 Matplotlib 生成散点图。 以下是打印散点图的代码示例。
fig, axes = plt.subplots(figsize = (18,10))
axes.scatter(df_boston['INDUS'], df_boston['TAX'])
axes.set_xlabel('Non-retail business acres per town')
axes.set_ylabel('Tax Rate')
plt.show()
输出:
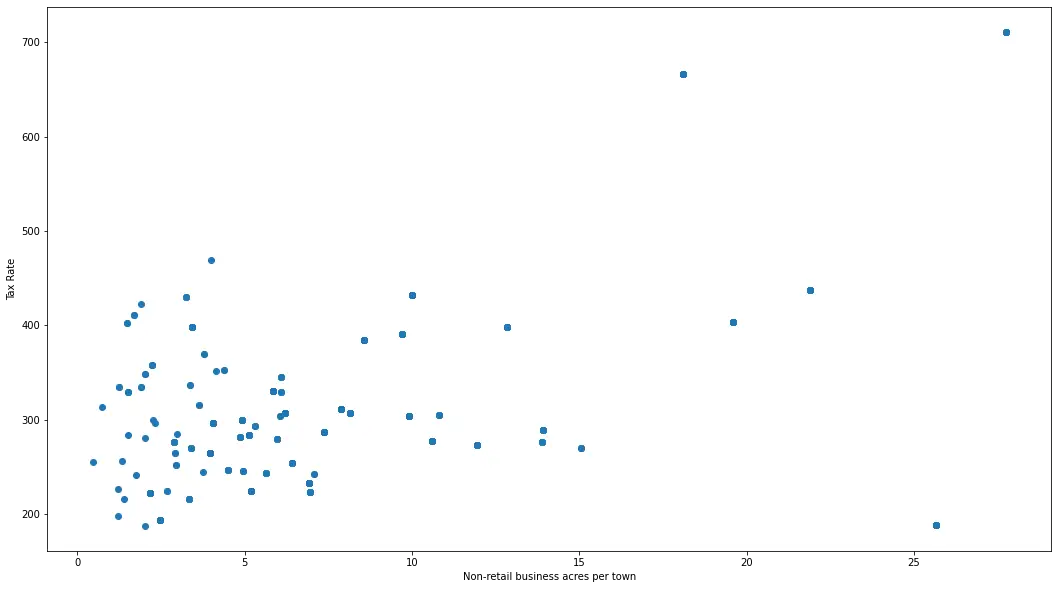
通过眼球估计,我们通常可以说在 x 轴上,大于 20 的值看起来像异常值,而在 y 轴上,大于 500 的值看起来像异常值。 我们可以将其用作去除异常值的标准。
我们将使用我们之前使用的相同 numpy 函数来检测符合此标准的索引。
print(np.where((df_boston['INDUS']>20) & (df_boston['TAX']>500)))
输出:

在 Python 中检测异常值的数学方法
计算 Z 分数以检测 Python 中的异常值
Z 分数(也称为标准分数)是一种统计数据,用于衡量数据点与平均值之间的标准偏差。 Z 分数越大,表明数据点离均值越远。
这很重要,因为大多数数据点都接近正态分布数据集中的平均值。 具有较大 Z 分数的数据点距离大多数数据点较远,很可能是异常值。
我们可以使用 Scipy 的实用程序来生成 Z 分数。 我们将再次选择数据集中的特定列来应用该方法。
from scipy import stats
z = stats.zscore(df_boston['DIS'])
z_abs = np.abs(z)
上面代码的第一行只是导入库。 第二行使用 scipy.zscore 方法计算所选数据集中每个数据点的 Z 分数。
第三行有一个 numpy 函数,用于将所有值转换为正值。 这有助于我们应用一个简单的过滤器。
打印数组将向我们展示如下内容:
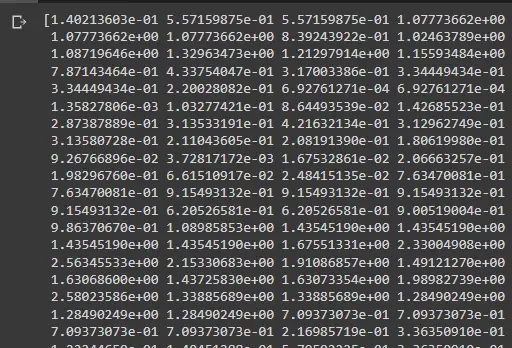
此图像不包括所有点,但您可以通过打印 z_abs 来显示它。
我们现在必须确定哪些点算作异常值的标准。 使用正态分布时,高于平均值三个标准差的数据点被视为异常值。
这是因为 99.7% 的点在正态分布均值的 3 个标准差范围内。 这意味着应删除所有 Z 分数大于 3 的点。
我们将再次使用 np.where 函数来查找离群值索引。 了解有关 np.where 函数的更多信息。
print(np.where(z_abs > 3))
输出:

计算四分位数间距以检测 Python 中的异常值
这是我们将讨论的最后一种方法。 这种方法在研究中非常常用,通过去除异常值来清理数据。
四分位数间距 (IQR) 是数据的第三个四分位数和第一个四分位数之间的差值。 我们将 Q1 定义为第一个四分位数,这意味着 25% 的数据位于最小值和 Q1 之间。
我们将 Q3 定义为数据的第三个四分位数,这意味着 75% 的数据位于数据集最小值和 Q3 之间。
通过这些定义,我们可以定义我们的上限和下限。 低于下限和高于上限的任何数据点都将被视为异常值。
Lower bound = Q1 - (1.5 * IQR)
Upper bound = Q3 + (1.5 * IQR)
1.5 可能看起来很武断,但它具有数学意义。 如果您对其详细数学感兴趣,请查看这篇文章
您需要知道这大致相当于找到与均值相差至少 3 个标准差的数据(如果我们的数据呈正态分布)。 在实践中,这种方法非常有效。
在 Python 中,我们可以使用 NumPy 函数 percentile() 找到 Q1 和 Q3,然后找到 IQR。
Q1 = np.percentile(df_boston['DIS'], 25, interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75, interpolation = 'midpoint')
IQR = Q3 - Q1
在我们的数据集中,我们打印 IQR 并得到以下信息:

我们现在将定义我们的上限和下限如下:
upper_bound = df_boston['DIS'] >= (Q3+1.5*IQR)
lower_bound = df_boston['DIS'] <= (Q1-1.5*IQR)
再一次,我们可以使用 np.where 获得符合条件的点的索引。
print(np.where(upper_bound))
print(np.where(lower_bound))
输出:

在 Python 中从 DataFrame 中删除异常值
我们将使用 dataframe.drop 函数删除离群点。 单击此处了解有关该功能的更多信息。
为此,我们必须将包含离群值索引的列表传递给函数。 我们可以这样做:
upper_points = np.where(upper_bound)
df_boston.drop(upper_points[0], inplace=True)
为了验证点是否已被删除,我们可以打印数据的形状以查看剩余的条目数。
print(df_boston.shape)
df_boston.drop(upper_points[0], inplace=True)
print(df_boston.shape)
输出:
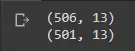
恭喜! 这证实我们已成功删除异常值。 您可以使用我们上面使用的方法传递任何索引列表,并将它们传递给 drop 函数。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

