Python 中的线程锁
本教程将讨论在 Python 中使用线程锁的不同方法。
Python 中的竞争条件
竞争条件是当多个线程尝试修改同一个共享变量时出现的问题。所有线程同时从共享变量中读取相同的值。然后,所有线程尝试修改共享变量的值。但是,该变量最终只会存储最后一个线程的值,因为它会覆盖前一个线程写入的值。从这个意义上说,所有线程之间存在竞争,以查看最终哪个线程修改了变量的值。以下代码中的示例演示了这种现象。
from threading import Thread
counter = 0
def increase(by):
global counter
local_counter = counter
local_counter += by
counter = local_counter
print(f'counter={counter}')
t1 = Thread(target=increase, args=(10,))
t2 = Thread(target=increase, args=(20,))
t1.start()
t2.start()
t1.join()
t2.join()
print(f'The final counter is {counter}')
输出:
counter=10
counter=20
The final counter is 20
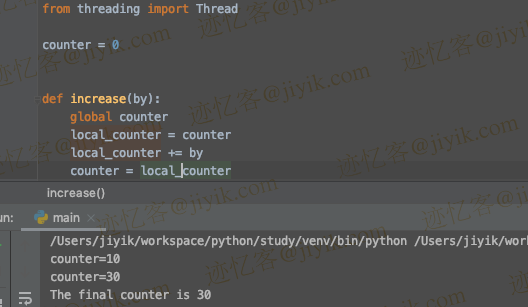
我们有一个全局共享变量 counter = 0 和两个线程 t1 和 t2。线程 t1 尝试将 counter 的值增加 10,线程 t2 尝试将 counter 的值增加 20。在上面的代码中,我们同时运行两个线程并尝试修改值计数器。根据上述逻辑,counter 的最终值应该是 30。但是,由于竞争条件,counter 要么是 10,要么是 20。
Python 中的线程锁
线程锁用于防止竞争条件。线程锁在被一个线程使用时锁定对共享变量的访问,以便任何其他线程无法访问它,然后在线程不使用共享变量时移除锁,以便其他线程可以使用该变量进行处理。threading 模块中的 Lock class 用于在 Python 中创建线程锁。acquire() 方法用于锁定对共享变量的访问,而 release() 方法用于解锁锁定。如果在未锁定的锁上使用 release() 方法会引发 RuntimeError 异常。
from threading import Thread, Lock
counter = 0
def increase(by, lock):
global counter
lock.acquire()
local_counter = counter
local_counter += by
counter = local_counter
print(f'counter={counter}')
lock.release()
lock = Lock()
t1 = Thread(target=increase, args=(10, lock))
t2 = Thread(target=increase, args=(20, lock))
t1.start()
t2.start()
t1.join()
t2.join()
print(f'The final counter is {counter}')
输出:
counter=10
counter=30
The final counter is 30
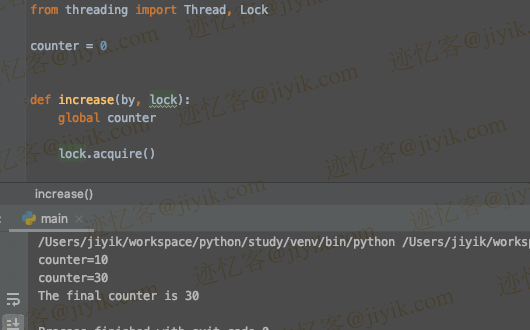
我们创建了一个全局共享变量 counter=0 和两个线程 t1 和 t2。两个线程都针对相同的 increase() 函数。increase(by, lock) 函数有两个参数。第一个参数是它将增加 counter 的数量,第二个参数是 Lock 类的实例。除了前面的声明,我们还在 Python 的 threading 模块中创建了一个 Lock 类的实例 lock。increase(by, lock) 函数中的这个 lock 参数使用 lock.acquire() 函数锁定对 counter 变量的访问,同时它被任何线程修改,并使用 lock 解锁锁定。release() 函数,当一个线程修改了 counter 变量。线程 t1 将 counter 的值增加 10,线程 t2 将 counter 的值增加 20。 由于线程锁定,不会发生竞争条件,最终 counter 的值为 30。
在 Python 中使用 with lock: 的线程锁
前一种方法的问题在于,当一个线程完成处理时,我们必须小心地解锁每个锁定的变量。如果没有正确完成,我们的共享变量将只会被第一个线程访问,而其他线程将无法访问共享变量。这个问题可以通过使用上下文管理来避免。我们可以使用 with lock: 并将我们所有的关键代码放在这个块中。这是防止竞争条件的更简单的方法。以下代码片段显示了使用 with lock: 来防止 Python 中的竞争条件。
from threading import Thread, Lock
counter = 0
def increase(by, lock):
global counter
with lock:
local_counter = counter
local_counter += by
counter = local_counter
print(f'counter={counter}')
lock = Lock()
t1 = Thread(target=increase, args=(10, lock))
t2 = Thread(target=increase, args=(20, lock))
t1.start()
t2.start()
t1.join()
t2.join()
print(f'The final counter is {counter}')
输出:
counter=10
counter=30
The final counter is 30

我们将增加 counter 的代码放在 with lock: 块中。线程 t1 将 counter 的值增加 10,线程 t2 将 counter 的值增加 20。没有发生竞争条件,counter 的最终值为 30。此外,我们不需要担心解锁线程锁。
两种方法都完美地完成了它们的工作,即两种方法都可以防止竞争条件的发生,但是第二种方法远远优于第一种,因为它可以避免我们为处理线程锁的锁定和解锁而头疼。与第一种方法相比,它编写起来也更简洁,更易于阅读。
注: 本文转载自:delftstack 。对于文中示例已都进行过运行。如遇到错误代码会进行相应的修改,修改正确之后才会在文中发布。如大家在运行示例中发现有代码错误的,请及时告知。
相关文章
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串
在 Python Pandas 中使用 str.split 将字符串拆分为两个列表列
发布时间:2024/04/24 浏览次数:1124 分类:Python
-
本教程介绍如何使用 pandas str.split() 函数将字符串拆分为两个列表列。
在 Pandas 中将 Timedelta 转换为 Int
发布时间:2024/04/23 浏览次数:231 分类:Python
-
可以使用 Pandas 中的 dt 属性将 timedelta 转换为整数。
Python 中的 Pandas 插入方法
发布时间:2024/04/23 浏览次数:112 分类:Python
-
本教程介绍了如何在 Pandas DataFrame 中使用 insert 方法在 DataFrame 中插入一列。
使用 Python 将 Pandas DataFrame 保存为 HTML
发布时间:2024/04/21 浏览次数:106 分类:Python
-
本教程演示如何将 Pandas DataFrame 转换为 Python 中的 HTML 表格。
如何将 Python 字典转换为 Pandas DataFrame
发布时间:2024/04/20 浏览次数:73 分类:Python
-
本教程演示如何将 python 字典转换为 Pandas DataFrame,例如使用 Pandas DataFrame 构造函数或 from_dict 方法。
如何在 Pandas 中将 DataFrame 列转换为日期时间
发布时间:2024/04/20 浏览次数:101 分类:Python
-
本文介绍如何将 Pandas DataFrame 列转换为 Python 日期时间。

