JavaScript 存在 Unicode 问题
JavaScript 处理 Unicode 的方式……至少可以说是令人惊讶的。 这篇文章解释了 JavaScript 中与 Unicode 相关的痛点,提供了常见问题的解决方案,并解释了 ECMAScript 6 标准如何改善这种情况。
Unicode 基础知识
在我们仔细研究 JavaScript 之前,让我们确保在谈到 Unicode 时我们都在同一个页面上。
最简单的做法是将 Unicode 视为一个数据库,它将我们能想到的任何符号映射到一个称为其代码点的数字,并映射到一个唯一的名称。 这样,不用实际使用符号本身就可以很容易地引用特定符号。 例子:
- A 是 U+0041 拉丁文大写字母 A。
- a 是 U+0061 拉丁文小写字母 A。
- © 是 U+00A9 版权标志。
- ☃ 是 U+2603 雪人。
代码点通常被格式化为十六进制数字,零填充到至少四位数字,带有 U+ 前缀。
可能的代码点值范围从 U+0000 到 U+10FFFF。 那是超过 110 万个可能的符号。 为了让事情井井有条,Unicode 将这一范围的代码点划分为 17 个平面,每个平面由大约 65,000 个代码点组成。
第一个平面 (U+0000 → U+FFFF) 被称为基本多语言平面或 BMP,它可能是最重要的平面,因为它包含所有最常用的符号。 大多数时候,对于英文文本文档,我们不需要 BMP 之外的任何代码点。 就像任何其他 Unicode 平面一样,它包含大约 65,000 个符号。
这给我们留下了大约 100 万个位于 BMP 之外的其他代码点 (U+010000 → U+10FFFF)。 这些代码点所属的平面称为补充平面或星体平面。
Astral 代码点很容易识别:如果我们需要 4 个以上的十六进制数字来表示代码点,它就是一个 astral 代码点。
现在我们对 Unicode 有了基本的了解,让我们看看它如何应用于 JavaScript 字符串。
转义序列
你以前可能见过这样的事情:
>> '\x41\x42\x43'
'ABC'
>> '\x61\x62\x63'
'abc'
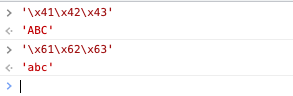
这些被称为十六进制转义序列。 它们由两个引用匹配代码点的十六进制数字组成。 例如,\x41 表示 U+0041 拉丁文大写字母 A。这些转义序列可用于 U+0000 到 U+00FF 范围内的代码点。
以下类型的转义也很常见:
>> '\u0041\u0042\u0043'
'ABC'
>> 'I \u2661 JavaScript!'
'I ♡ JavaScript!'
这些被称为 Unicode 转义序列。 它们由 4 个代表代码点的十六进制数字组成。 例如,\u2661 表示 U+2661 白心套装。 这些转义序列可用于从 U+0000 到 U+FFFF 范围内的代码点,即整个基本多语言平面。
但是所有其他位面——星光位面呢? 我们需要 4 个以上的十六进制数字来表示它们的代码点……那么我们如何转义它们呢?
在 ECMAScript 6 中这很容易,因为它引入了一种新型的转义序列:Unicode 代码点转义。 例如:
>> '\u{41}\u{42}\u{43}'
'ABC'
>> '\u{1F4A9}'
'💩' // U+1F4A9 PILE OF POO
在大括号之间最多可以使用六个十六进制数字,这足以表示所有 Unicode 代码点。 因此,通过使用这种类型的转义序列,您可以根据代码点轻松转义任何 Unicode 符号。
为了向后兼容 ECMAScript 5 和更旧的环境,不幸的解决方案是使用代理对:
>> '\uD83D\uDCA9'
'💩' // U+1F4A9 PILE OF POO
在那种情况下,每个转义代表代理一半的代码点。 两个替代的一半形成一个星体符号。
请注意,代理代码点看起来与原始代码点完全不同。 有一些公式可以根据给定的星体代码点计算代理,反之亦然——根据其代理对计算原始星体代码点。
使用代理对,可以表示所有星体代码点(即从 U+010000 到 U+10FFFF)……但是使用单个转义符表示 BMP 符号和两个转义符表示星体符号的整个概念令人困惑,并且有很多 烦人的后果。
计算 JavaScript 字符串中的符号
例如,假设我们要计算给定字符串中符号的数量。 你会怎么做?
我的第一个想法可能是简单地使用 length 属性。
>> 'A'.length // U+0041 LATIN CAPITAL LETTER A
1
>> 'A' == '\u0041'
true
>> 'B'.length // U+0042 LATIN CAPITAL LETTER B
1
>> 'B' == '\u0042'
true
在这些示例中,字符串的 length 属性恰好反映了字符数。 这是有道理的:如果我们使用转义序列来表示符号,很明显我们只需要对每个符号进行一次转义。 但情况并非总是如此! 这是一个稍微不同的例子:
>> '𝐀'.length // U+1D400 MATHEMATICAL BOLD CAPITAL A
2
>> '𝐀' == '\uD835\uDC00'
true
>> '𝐁'.length // U+1D401 MATHEMATICAL BOLD CAPITAL B
2
>> '𝐁' == '\uD835\uDC01'
true
>> '💩'.length // U+1F4A9 PILE OF POO
2
>> '💩' == '\uD83D\uDCA9'
true
在内部,JavaScript 将星体符号表示为代理项对,并将单独的代理项部分公开为单独的“字符”。 如果我们只使用与 ECMAScript 5 兼容的转义序列来表示符号,我们会发现每个星体符号都需要两个转义符。 这很令人困惑,因为人类通常会根据 Unicode 符号或字素来思考。
计算星体符号个数
回到问题:如何准确统计 JavaScript 字符串中的符号个数? 诀窍是正确考虑代理对,并且只将每对计为单个符号。 你可以使用这样的东西:
var regexAstralSymbols = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g;
function countSymbols(string) {
return string
// Replace every surrogate pair with a BMP symbol.
.replace(regexAstralSymbols, '_')
// …and *then* get the length.
.length;
}
或者,如果我们使用 Punycode.js(随 Node.js 一起提供),请使用其实用方法在 JavaScript 字符串和 Unicode 代码点之间进行转换。 punycode.ucs2.decode 方法接受一个字符串并返回一个 Unicode 代码点数组; 每个符号一个项目。
function countSymbols(string) {
return punycode.ucs2.decode(string).length;
}
在 ES6 中,你可以用 Array.from 做一些类似的事情,它使用字符串的迭代器将它拆分成一个字符串数组,每个字符串包含一个符号:
function countSymbols(string) {
return Array.from(string).length;
}
或者,使用扩展运算符 ...:
function countSymbols(string) {
return [...string].length;
}
使用这些实现中的任何一个,我们现在能够正确计算代码点,从而获得更准确的结果:
>> countSymbols('A') // U+0041 LATIN CAPITAL LETTER A
1
>> countSymbols('𝐀') // U+1D400 MATHEMATICAL BOLD CAPITAL A
1
>> countSymbols('💩') // U+1F4A9 PILE OF POO
1
计算相似
但如果我们真的很迂腐,计算字符串中符号的数量就更复杂了。 考虑这个例子:
>> 'mañana' == 'mañana'
false
JavaScript 告诉我们这些字符串是不同的,但在视觉上,没有办法分辨! 那么那里发生了什么?原因如下:
>> 'ma\xF1ana' == 'man\u0303ana'
false
>> 'ma\xF1ana'.length
6
>> 'man\u0303ana'.length
7
第一个字符串包含 U+00F1 LATIN SMALL LETTER N WITH TILDE,而第二个字符串使用两个单独的代码点(U+006E LATIN SMALL LETTER N 和 U+0303 COMBINING TILDE)来创建相同的字形。 这就解释了为什么它们不相等,以及为什么它们的长度不同。
然而,如果我们想像人类一样计算这些字符串中符号的数量,我们希望两个字符串的答案都是 6,因为这是每个字符串中视觉上可区分的字形的数量。 我们怎样才能做到这一点?
在 ECMAScript 6 中,解决方案相当简单:
function countSymbolsPedantically(string) {
// Unicode Normalization, NFC form, to account for lookalikes:
var normalized = string.normalize('NFC');
// Account for astral symbols / surrogates, just like we did before:
return punycode.ucs2.decode(normalized).length;
}
String.prototype 上的 normalize 方法执行 Unicode 规范化,这说明了这些差异。 如果单个代码点表示与后跟组合标记的另一个代码点相同的字形,它将规范化为单个代码点形式。
>> countSymbolsPedantically('mañana') // U+00F1
6
>> countSymbolsPedantically('mañana') // U+006E + U+0303
6
为了向后兼容 ECMAScript 5 和更旧的环境,可以使用 String.prototype.normalize polyfill。
统计其他组合标记
不过,这仍然不完美——应用了多个组合标记的代码点总是会产生一个单一的视觉字形,但可能没有规范化的形式,在这种情况下规范化无济于事。 例如:
>> 'q\u0307\u0323'.normalize('NFC') // `q̣̇`
'q\u0307\u0323'
>> countSymbolsPedantically('q\u0307\u0323')
3 // not 1
>> countSymbolsPedantically('Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞')
74 // not 6
如果需要更准确的解决方案,我们可以使用正则表达式从输入字符串中删除任何组合标记。
// Note: replace the following regular expression with its transpiled equivalent
// to make it work in old environments. https://mths.be/bwm
var regexSymbolWithCombiningMarks = /(\P{Mark})(\p{Mark}+)/gu;
function countSymbolsIgnoringCombiningMarks(string) {
// Remove any combining marks, leaving only the symbols they belong to:
var stripped = string.replace(regexSymbolWithCombiningMarks, function($0, symbol, combiningMarks) {
return symbol;
});
// Account for astral symbols / surrogates, just like we did before:
return punycode.ucs2.decode(stripped).length;
}
此函数删除任何组合标记,只留下它们所属的符号。 任何不匹配的组合标记(在字符串的开头)都保持不变。 这个解决方案甚至可以在 ECMAScript 3 环境中工作,并且它提供了迄今为止最准确的结果:
>> countSymbolsIgnoringCombiningMarks('q\u0307\u0323')
1
>> countSymbolsIgnoringCombiningMarks('Z͑ͫ̓ͪ̂ͫ̽͏̴̙̤̞͉͚̯̞̠͍A̴̵̜̰͔ͫ͗͢L̠ͨͧͩ͘G̴̻͈͍͔̹̑͗̎̅͛́Ǫ̵̹̻̝̳͂̌̌͘!͖̬̰̙̗̿̋ͥͥ̂ͣ̐́́͜͞')
6
在 JavaScript 中反转字符串
这是一个类似问题的示例:在 JavaScript 中反转字符串。 这有多难,对吧? 这个问题的一个常见的、非常简单的解决方案如下:
// naive solution
function reverse(string) {
return string.split('').reverse().join('');
}
在很多情况下它似乎工作正常:
>> reverse('abc')
'cba'
>> reverse('mañana') // U+00F1
'anañam'
然而,它完全弄乱了包含组合标记或星体符号的字符串。
>> reverse('mañana') // U+006E + U+0303
'anãnam' // note: the `~` is now applied to the `a` instead of the `n`
>> reverse('💩') // U+1F4A9
'��' // `'\uDCA9\uD83D'`, the surrogate pair for `💩` in the wrong order
要在 ES6 中正确反转星体符号,可以将字符串迭代器与 Array.from 结合使用:
// slightly better solution that relies on ES6 StringIterator and `Array.from`
function reverse(string) {
return Array.from(string).reverse().join('');
}
不过,这仍然没有解决涉及组合标记的问题。
事实上:通过将任何组合标记的位置与它们所属的符号交换,以及在进一步处理字符串之前反转任何代理对,可以成功避免这些问题。
// using Esrever (https://mths.be/esrever)
>> esrever.reverse('mañana') // U+006E + U+0303
'anañam'
>> esrever.reverse('💩') // U+1F4A9
'💩' // U+1F4A9
字符串方法中的 Unicode 问题
此行为也会影响其他字符串方法。
将代码点转换为符号
String.fromCharCode 允许我们创建基于 Unicode 代码点的字符串。 但它仅适用于 BMP 范围内的代码点(即从 U+0000 到 U+FFFF)。 如果我们将它与星体代码点一起使用,会得到意想不到的结果。
>> String.fromCharCode(0x0041) // U+0041
'A' // U+0041
>> String.fromCharCode(0x1F4A9) // U+1F4A9
'' // U+F4A9, not U+1F4A9
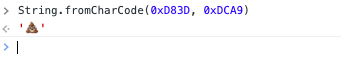
唯一的解决方法是自己计算代理项的代码点,并将它们作为单独的参数传递。
>> String.fromCharCode(0xD83D, 0xDCA9)
'💩' // U+1F4A9
如果你不想经历计算代理项一半的麻烦,你可以再次求助于 Punycode.js 的实用方法:
>> punycode.ucs2.encode([ 0x1F4A9 ])
'💩' // U+1F4A9
幸运的是,ECMAScript 6 引入了 String.fromCodePoint(codePoint) ,它可以正确处理星体符号。 它可用于任何 Unicode 代码点,即从 U+000000 到 U+10FFFF。
>> String.fromCodePoint(0x1F4A9)
'💩' // U+1F4A9
为了向后兼容 ECMAScript 5 和更旧的环境,请使用 String.fromCodePoint() polyfill。
从字符串中获取符号
如果我们使用 String.prototype.charAt(position) 来检索包含 poo 字符堆的字符串中的第一个符号,我们将只会得到第一个代理项的一半而不是整个符号。
>> '💩'.charAt(0) // U+1F4A9
'\uD83D' // U+D83D, i.e. the first surrogate half for U+1F4A9
有人提议在 ECMAScript 7 中引入 String.prototype.at(position)。它类似于 charAt,只是它尽可能处理完整的符号而不是代理项的一半。
>> '💩'.at(0) // U+1F4A9
'💩' // U+1F4A9
为了向后兼容 ECMAScript 5 和更旧的环境,可以使用 String.prototype.at() polyfill/prollyfill。
从字符串中获取代码点
同样,如果我们使用 String.prototype.charCodeAt(position) 检索字符串中第一个符号的代码点,我们将获得第一个代理项一半的代码点,而不是一堆 poo 字符的代码点。
>> '💩'.charCodeAt(0)
0xD83D
幸运的是,ECMAScript 6 引入了 String.prototype.codePointAt(position),它类似于 charCodeAt,只是它尽可能处理完整的符号而不是代理项的一半。
>> '💩'.codePointAt(0)
0x1F4A9
为了向后兼容 ECMAScript 5 和更旧的环境,请使用 String.prototype.codePointAt() polyfill。
遍历字符串中的所有符号
假设我们想遍历字符串中的每个符号并对每个单独的符号执行某些操作。
在 ECMAScript 5 中,你必须编写大量样板代码来解释代理对:
function getSymbols(string) {
var index = 0;
var length = string.length;
var output = [];
for (; index < length; ++index) {
var charCode = string.charCodeAt(index);
if (charCode >= 0xD800 && charCode <= 0xDBFF) {
charCode = string.charCodeAt(index + 1);
if (charCode >= 0xDC00 && charCode <= 0xDFFF) {
output.push(string.slice(index, index + 2));
++index;
continue;
}
}
output.push(string.charAt(index));
}
return output;
}
var symbols = getSymbols('💩');
symbols.forEach(function(symbol) {
assert(symbol == '💩');
});
或者,我们可以使用正则表达式,例如 var regexCodePoint = /[^\uD800-\uDFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDFFF]/g; 并遍历匹配。
在 ECMAScript 6 中,我们可以简单地使用 for...of。 字符串迭代器处理整个符号而不是代理项对。
for (const symbol of '💩') {
assert(symbol == '💩');
}
不幸的是,没有办法填充它,因为 for...of 是一个语法级别的结构。
其他事宜
这种行为会影响几乎所有的字符串方法,包括那些没有在这里明确提到的方法(例如 String.prototype.substring、String.prototype.slice 等),所以在使用它们时要小心。
正则表达式中的 Unicode 问题
匹配代码点和 Unicode 标量值
正则表达式中的点运算符 . 仅匹配单个“字符”……但由于 JavaScript 将代理项暴露为单独的“字符”,因此它永远不会匹配星体符号。
>> /foo.bar/.test('foo💩bar')
false
让我们考虑一下……我们可以使用什么正则表达式来匹配任何 Unicode 符号? 有任何想法吗? 如图所示,。 是不够的,因为它不匹配换行符或整个星体符号。
>> /^.$/.test('💩')
false
为了正确匹配换行符,我们可以使用 [\s\S] 代替,但这仍然无法匹配整个星体符号。
>> /^[\s\S]$/.test('💩')
false
事实证明,匹配任何 Unicode 代码点的正则表达式根本不是很简单:
>> /[\0-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF]/.test('💩') // wtf
true
当然,你不会想手写这些正则表达式,更不用说调试它们了。 为了生成前面的正则表达式,我使用了 Regenerate,这是一个可以根据代码点或符号列表轻松创建正则表达式的库:
>> regenerate().addRange(0x0, 0x10FFFF).toString()
'[\0-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF]'
从左到右,此正则表达式匹配 BMP 符号、代理项对(星体符号)或单独的代理项。
虽然在 JavaScript 字符串中技术上允许单独的代理项,但它们本身不会映射到任何符号,因此应该避免。 术语 Unicode 标量值是指除代理项代码点之外的所有代码点。 这是一个匹配任何 Unicode 标量值的正则表达式:
>> regenerate()
.addRange(0x0, 0x10FFFF) // all Unicode code points
.removeRange(0xD800, 0xDBFF) // minus high surrogates
.removeRange(0xDC00, 0xDFFF) // minus low surrogates
.toRegExp()
/[\0-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]/
Regenerate 旨在用作构建脚本的一部分,以创建复杂的正则表达式,同时仍然保持生成它们的脚本的可读性和易于维护性。
ECMAScript 6 有望使用正则表达式的 u 标志导致 . 运算符来匹配整个代码点而不是代理项的一半。
>> /foo.bar/.test('foo💩bar')
false
>> /foo.bar/u.test('foo💩bar')
true
注意:.仍然不会匹配换行符。 当设置u标志时,.等效于以下向后兼容的正则表达式模式:>> regenerate() .addRange(0x0, 0x10FFFF) // all Unicode code points .remove( // minus `LineTerminator`s (https://ecma-international.org/ecma-262/5.1/#sec-7.3): 0x000A, // Line Feed <LF> 0x000D, // Carriage Return <CR> 0x2028, // Line Separator <LS> 0x2029 // Paragraph Separator <PS> ) .toString(); '[\0-\t\x0B\f\x0E-\u2027\u202A-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF]' >> /foo(?:[\0-\t\x0B\f\x0E-\u2027\u202A-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF])bar/u.test('foo💩bar')
角色类别中的星体范围
考虑到 /[a-c]/ 匹配从 U+0061 拉丁小写字母 A 到 U+0063 拉丁小写字母 C 的任何符号,/[💩-💫]/ 可能会匹配从 U+1F4A9 PILE OF POO 到 U+1F4AB DIZZY SYMBOL。 然而事实并非如此:
>> /[💩-💫]/
SyntaxError: Invalid regular expression: Range out of order in character class

发生这种情况的原因是因为该正则表达式等效于:
>> /[\uD83D\uDCA9-\uD83D\uDCAB]/
SyntaxError: Invalid regular expression: Range out of order in character class
与我们想要的匹配 U+1F4A9、U+1F4AA 和 U+1F4AB 不同,正则表达式匹配:
- U+D83D(高代理),或者……
- 从 U+DCA9 到 U+D83D 的范围(这是无效的,因为起始代码点大于标记范围结束的代码点),或者……
- U+DCAB(低代理)。
ECMAScript 6 允许我们再次使用神奇的 /u 标志来选择更合理的行为。
>> /[\uD83D\uDCA9-\uD83D\uDCAB]/u.test('\uD83D\uDCA9') // match U+1F4A9
true
>> /[\u{1F4A9}-\u{1F4AB}]/u.test('\u{1F4A9}') // match U+1F4A9
true
>> /[💩-💫]/u.test('💩') // match U+1F4A9
true
>> /[\uD83D\uDCA9-\uD83D\uDCAB]/u.test('\uD83D\uDCAA') // match U+1F4AA
true
>> /[\u{1F4A9}-\u{1F4AB}]/u.test('\u{1F4AA}') // match U+1F4AA
true
>> /[💩-💫]/u.test('💪') // match U+1F4AA
true
>> /[\uD83D\uDCA9-\uD83D\uDCAB]/u.test('\uD83D\uDCAB') // match U+1F4AB
true
>> /[\u{1F4A9}-\u{1F4AB}]/u.test('\u{1F4AB}') // match U+1F4AB
true
>> /[💩-💫]/u.test('💫') // match U+1F4AB
true
遗憾的是,这个解决方案不能向后兼容 ECMAScript 5 和更旧的环境。 如果这是一个问题,我们应该使用 Regenerate 来生成与 ES5 兼容的正则表达式,这些正则表达式处理星体范围或一般的星体符号:
>> regenerate().addRange('💩', '💫')
'\uD83D[\uDCA9-\uDCAB]'
>> /^\uD83D[\uDCA9-\uDCAB]$/.test('💩') // match U+1F4A9
true
>> /^\uD83D[\uDCA9-\uDCAB]$/.test('💪') // match U+1F4AA
true
>> /^\uD83D[\uDCA9-\uDCAB]$/.test('💫') // match U+1F4AB
true
更新:另一种选择是使用正则表达式或包含正则表达式的转译器来转译您的代码。 我写了一篇单独的博客文章,详细介绍了 ES6 中支持 Unicode 的正则表达式 。
相关文章
Do you understand JavaScript closures?
发布时间:2025/02/21 浏览次数:108 分类:JavaScript
-
The function of a closure can be inferred from its name, suggesting that it is related to the concept of scope. A closure itself is a core concept in JavaScript, and being a core concept, it is naturally also a difficult one.
Do you know about the hidden traps in variables in JavaScript?
发布时间:2025/02/21 浏览次数:178 分类:JavaScript
-
Whether you're just starting to learn JavaScript or have been using it for a long time, I believe you'll encounter some traps related to JavaScript variable scope. The goal is to identify these traps before you fall into them, in order to av
How much do you know about the Prototype Chain?
发布时间:2025/02/21 浏览次数:150 分类:JavaScript
-
The prototype chain can be considered one of the core features of JavaScript, and certainly one of its more challenging aspects. If you've learned other object-oriented programming languages, you may find it somewhat confusing when you start
如何在 JavaScript 中合并两个数组而不出现重复的情况
发布时间:2024/03/23 浏览次数:86 分类:JavaScript
-
本教程介绍了如何在 JavaScript 中合并两个数组,以及如何删除任何重复的数组。

