Python Selenium Headless:以 Headless 模式打开 Chrome 浏览器
本篇文章介绍了如何在 Python 中使用 Selenium 运行浏览器无头模式。
在 Python 中使用 Selenium 以无头模式运行 Chrome 浏览器
要说 headless 浏览器,你也可以称它们为真正的浏览器,只不过它们是在后台运行的; 您将无法在任何地方看到它们,但它们仍在后台运行。
在某些情况下您会需要这种无头浏览器。
因为当您在普通浏览器中工作时,您将看到 UI 出现并在本地系统上工作时操作其他应用程序。 因此,您将无法执行任何其他操作,从而导致附加操作在您面前运行。
假设您在无头模式下运行脚本。 为了让您可以继续工作,有几种浏览器可以使用无头模式,例如 phantomJS、HtmlUnit 等等,请参阅此处。
我们还为 Chrome 和 Firefox 提供了无头选项。 要了解如何使用 Chrome 在 Selenium 中以无头模式运行测试,我们首先需要创建一个 Python 文件。
我们将通过导入一些必需的类和模块来跳转到代码中。
import time
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
我们刚刚注意到 webdriver.Chrom() 有不同的选项,如下所示。
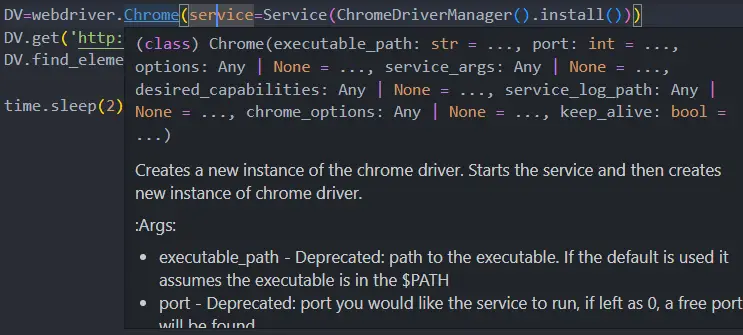
我们使用了一个应该启动 Chrome 会话的服务参数。 ChromeDriverManager()将帮助我们下载驱动程序并设置路径。
我们将使用 get() 方法并向其传递一个 URL,我们将在其中尝试查找搜索框,然后我们将使用 find_element() 来使用我们想要搜索的一些随机文本。
DV=webdriver.Chrome(service=Service(ChromeDriverManager().install()))
DV.get('http://www.google.com')
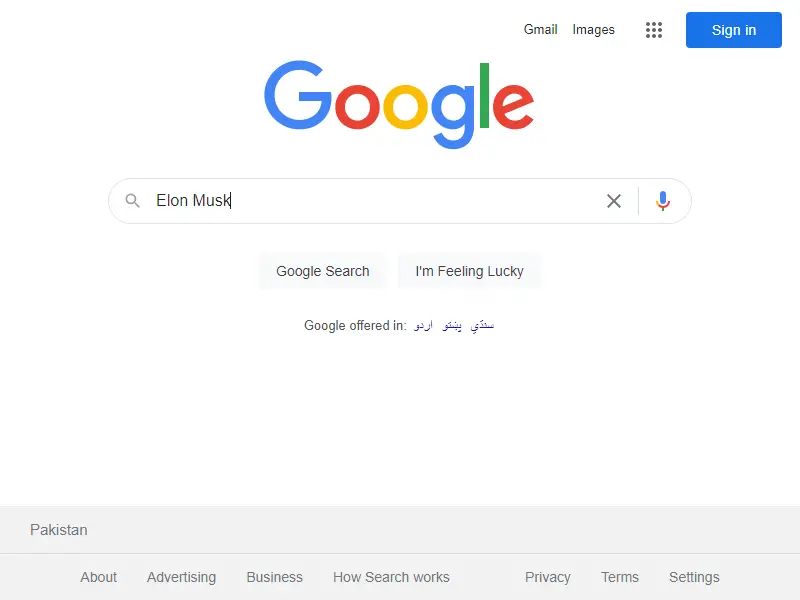
DV.find_element(By.NAME,'q').send_keys('Elon Musk')
time.sleep(2)
如果我们运行 python 脚本,您会注意到它不会在无头模式下运行并转到搜索框并搜索给定的查询。

现在我们将使用第二个参数,称为选项,并且我们需要提供选项。 我们有一个来自不同包的选项类; 您可以将其用于 Opera、Chrome 和 Firefox。
由于我们使用的是 Chrome,因此我们将使用 Chrome.options 中的 Options() 类。因此,我们将创建一个名为 OP 的对象来调用 Options() 类。
有两种选项或不同的方式可以在无头模式下运行测试。 首先,您必须使用 add_argument() 方法并在其中传递 --headless 。
为了实现这种效果,我们必须将 OP 传递给 options 参数。
import time
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
OP=Options()
OP.add_argument('--headless')
DV=webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=OP)
DV.get('http://www.google.com')
DV.find_element(By.NAME,'q').send_keys('Elon Musk')
完成后,您将看到测试将以无头模式运行,并且您将看不到任何内容。
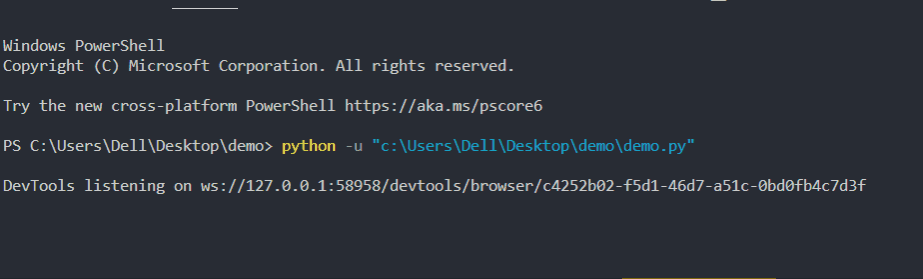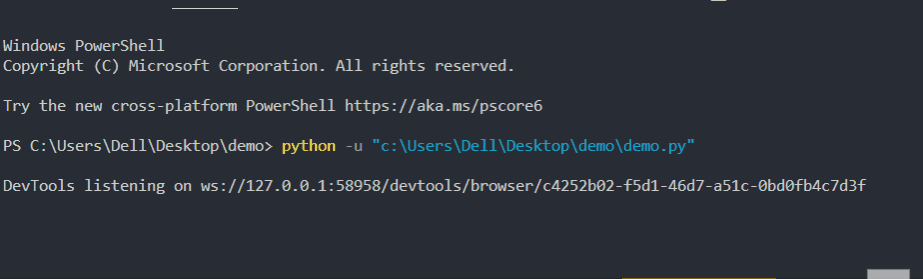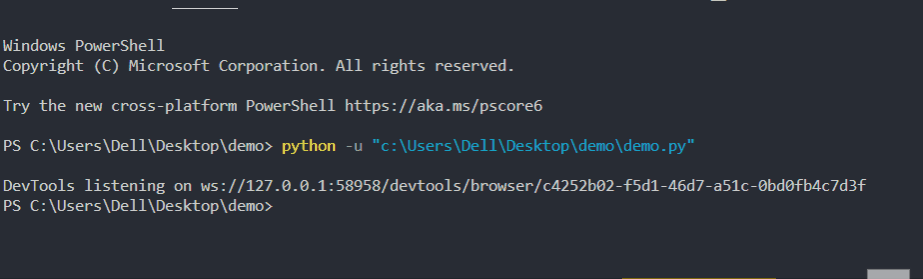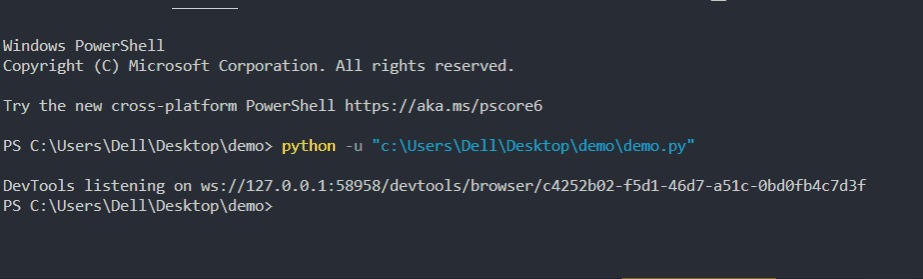
为了检查是否被搜索到,我们将使用 get_screenshot_as_file() 方法在无头模式下捕获屏幕截图。 它将以无头模式打开浏览器并立即抓取屏幕截图。
DV.get_screenshot_as_file(os.getcwd()+'/screenshot.png')
现在我们得到了后台发生的情况的屏幕截图。
假设你是一个经常犯拼写错误的人,有时很难记住 OP.add_argument('--headless')。 然后,我们还有一种选择:称为 headless 的类型属性。
默认情况下,它设置为False,您可以将其更改为True,因此不需要使用 add_argument()。
import time
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import os
OP=Options()
OP.headless=True
# OP.add_argument('--headless')
DV=webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=OP)
DV.get('http://www.google.com')
# DV.find_element(By.NAME,'q').send_keys('Elon Musk')
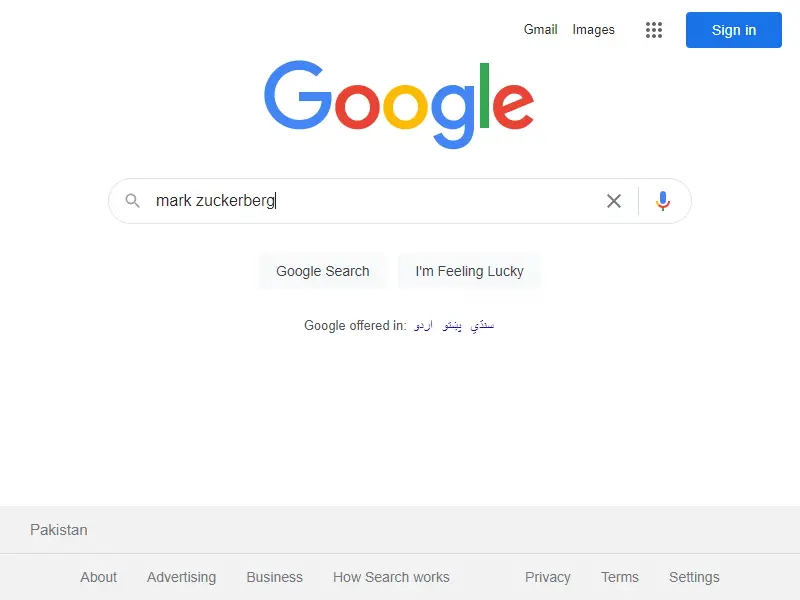
DV.find_element(By.NAME,'q').send_keys('mark zuckerberg')
DV.get_screenshot_as_file(os.getcwd()+'/screenshot.png')
重新运行此脚本后,我们获得了后台正在执行的操作的屏幕截图。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

