Python Teradata 连接
这篇 Python 文章将展示如何使用 Python 连接到 Teradata。 连接到 Teradata 并将表导出到 Pandas 的选项有很多。
本文将讨论一些基本的正确准则,并在讨论连接方式之前了解 Teradata 模块的工作原理。
Python 中的 Teradata 数据库
您可以使用 Python 和 Teradata 模块编写与 Teradata 数据库的强大交互脚本。
采用 udaSQL 理念提供了一个面向 DevOps 的 SQL 引擎,开发人员可以在其中专注于 SQL 逻辑,而不是执行外部配置、查询分段和日志记录。
我们可以在 MIT 许可证下下载 Teradata 模块。 下一步是从 PyPI 安装并下载包。
由于其开源性质,该模块受到社区的支持。 但是,客户和工程师无法获得该模块与第三方应用程序(例如 Teradata 的 ODBC 驱动程序和 sqlalchemy-Teradata)的互操作性支持。
使用 PyODBC 库在 Python 中连接到 Teradata
Pandas 数据框可以使用 SQL 创建,并使用 Teradata 数据框上传到 Teradata。
- Python 中安装了 Pandas 的环境。
- Teradata 数据库的主机名/IP 地址和连接方法已知。
- 您尝试连接到 Teradata 的计算机上必须安装 ODBC 驱动程序。
或者,如果您不确定 Teradata 的数据库详细信息,您可以联系公司的 DBA。 如果没有 Teradata ODBC 驱动程序,您可能需要使用 JDBC 和 PySpark。
在本篇文章中,我们还将讨论其他方法。
使用 PyODBC 库
借助 PyODBC,您可以使用 Python 轻松连接到 ODBC 数据库。 此外,该库还实现了 DB API 2.0 规范,并具有更多 Python 特性。
在您的 Python 环境中,您应该安装 PyODBC 库。 然后,您可以使用 Conda 或 Pip 安装该库。
pip install pyodbc
或者
conda install pyodbc
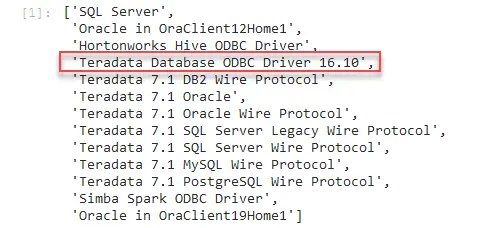
名为 pip 的 Python 包用于安装包、库和模块。 例如,在 pip 安装 PyODBC 模块和 Teradata 的 ODBC 驱动程序后,运行以下 Python 代码以列出现有驱动程序。
通过注意 Teradata 驱动程序的名称来验证 Teradata 是否出现在此列表中。
pyodbc.drivers()
以下代码栅栏显示了如何将 SQL 中的数据提取到 Pandas 数据框中。 但是,首先,检查下一个输出数据帧。
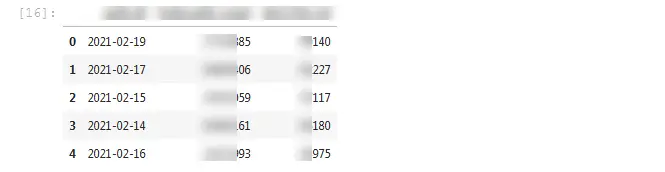
teradata_df.head()
Python 的 df.head() 始终返回 5 行以上的第一行。 因此,在这里,它将显示 Teradata 默认表中从 0-4 的前五行。
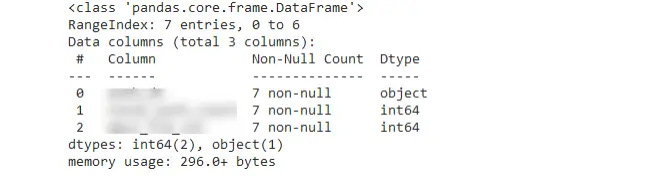
teradata_df.info()
连接字符串中有很多相关信息,例如主机名、驱动程序、用户名、密码和身份验证协议。
您可能需要传递可选参数,具体取决于您的 Teradata 设置。 与 ODBC 兼容的参数可以传递给 PyODBC。
拉取数据的过程很简单,但是上传数据的过程就比较复杂了。
- Pandas 数据框架需要转换为模式。
- 我们应该将数据帧分成块。 ODBC 数据库每次插入的最大大小为 1MB,因此如果数据帧很大,则会失败。
- 我们应该按顺序插入记录。
您可以按照以下代码上传数据框。
cnxn.commit()
print('Query complete. Running time is %s sec/s.'%(round(end_time-start_time)))
cnxn.commit() 命令将提交更改并使它们永久化。
在 Python 中使用 Teradata SQL 连接到 Teradata
要使用此软件包,您无需安装 Teradata 驱动程序(除此驱动程序外)。
import teradatasql
with teradatasql.connect(host='name', user='name', password='*****') as connect:
df = pd.read_sql(query, connect)
导入 terasql 后,Teradata 将使用以下参数主机、用户名和密码进行连接。 然后在成功连接后,将读取并执行查询。
另一种方法是使用 Giraffez 模块。 该模块具有许多有用的功能,例如 MLOAD、FASTLOAD、BULKEXPORT 等。但是,对于初学者来说只有很少的要求(例如 C/C++ 编译器、Teradata CLIv2 和 TPT API 头文件/lib 文件)。
请注意,上下文管理器已更新,以确保会话自 2018 年 7 月 13 日起关闭。 DF 可用于将数据发送到 Teradata。
使用rest方法,我们可以消除odbc施加的1MB限制以及对odbc驱动程序的依赖。 我们应该使用主机 IP 地址来代替驱动程序参数。
import teradata
import pandas as pd
udaExec = teradata.UdaExec (appName="webApp", version="1.0", logConsole=False)
with udaExec.connect(method="rest_one",system="DB_Name", username="user_name",
password="*******", host="HOST_IP_ADDRESS") as connect:
data = [tuple(x) for x in df.to_records(index=False)]
connect.executemany("INSERT INTO DATABASE.TABLEWITH5COL values(?,?,?,?,?)",data,batch=True)
为了避免 HY001[ODBC Teradata Driver] 内存分配错误,请在使用 ODBC Teradata 驱动程序时将数据分成小于 1MB 的块。 例如:
import teradata
import pandas as pd
import numpy as np
udaExec = teradata.UdaExec (appName="test", version="1.0", logConsole=False)
with udaExec.connect(method="odbc",system="DBName", username="User_Name",
password="*******", driver="Driver_Name") as connect:
chunks_df = np.array_split(huge_df, 100)
for i,_ in enumerate(chunks_df):
data = [tuple(x) for x in chuncks_df[i].to_records(index=False)]
connect.executemany("INSERT INTO DATABASE.TABLEWITH5COL v
以下是将 Teradata 与 Python 连接的另一种简单方法。
使用 Teradata 模块在 Python 中连接到 Teradata
如果已经安装了pip,执行以下命令可以直接安装该模块:
pip install Teradata
如果您还没有该软件包,可以通过以下 URL 下载该软件包:https://pypi.python.org/pypi/teradata。
下载 teradata 包后,将其解压缩,然后使用命令提示符导航到包含 setup.py 的目录,然后执行以下命令进行安装:
python setup.py install
示例代码:
import teradata
import sys
udaExec = teradata.UdaExec(
appName="HelloPeople", version="1.0", logConsole=False)
session = udaExec.connect(method="odbc", dsn="td16vm",
username="", password="", autocommit=True,
transactionMode="Teradata")
for row in session.execute('select getqueryband();'):
print(row)
for row in session.execute('select top 20 tablename, tablekind from dbc.tables;'):
print(row)
session.close()
input('Type <Enter> to exit...')
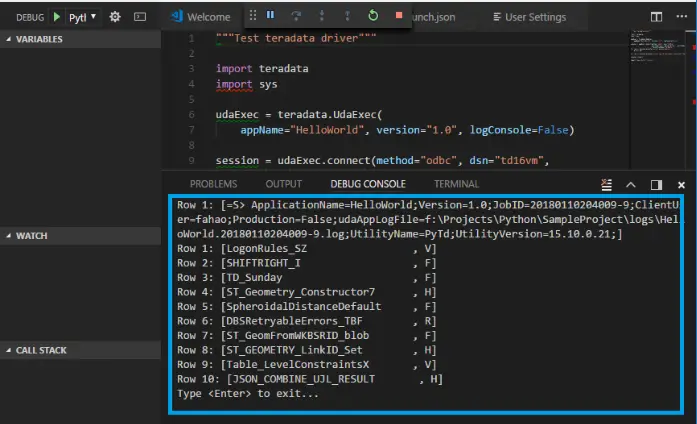
要连接到Teradata,我们必须配置这些参数:事务模式是Teradata; 连接方式为ODBC(另一种为REST),DSN为td16vm,在电脑中配置如下参数。
在下一步中,您需要为 Teradata 创建虚拟机。 以上示例代码的运行结果如下:
正如所讨论的,存在多种将 Teradata 连接到 Python 的方法。 通过分步指导,这里揭示了在 Python 中连接 Teradata 模块的所有可能方法。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

