使用 Python 获取 Redis 数据库中的所有键
如果你了解 JSON,就会熟悉 Redis 设计系统。 它使用键值结构和分布式内存方法来实现弹性数据库。
哈希、列表、集合、排序集合、字符串、JSON 和流是 Redis 支持的众多数据结构之一。 这个开源数据库支持不同的语言,包括 Python,如果您正在使用它开发后端系统,一些模块和包可以提供帮助。
您经常对数据库执行的许多操作之一是检索数据,在像 Redis 这样的数据库中,键对于实现此类操作很重要。
本文将讨论获取 Redis 数据库中的所有键。
使用 keys() 获取 Redis 数据库中的所有键
要使用 redis,我们需要安装它; 您可以查看 Redis 下载页面以了解操作方法。 对于 Linux 和 macOS 用户来说,这要容易得多; 但是,对于 Windows 用户,您可能必须使用适用于 Linux 的 Windows 子系统 (WSL2),并且您可以按照他们的说明视频指南进行操作。
假设您已经设置了 Redis 数据库,我们将安装 redis 包,它提供对 Redis 数据库的客户端访问。 要安装它,我们将使用 pip 命令。
pip install redis
输出:
Collecting redis
Downloading redis-4.3.4-py3-none-any.whl (246 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 246.2/246.2 kB 794.4 kB/s eta 0:00:00
Collecting deprecated>=1.2.3
Downloading Deprecated-1.2.13-py2.py3-none-any.whl (9.6 kB)
Collecting async-timeout>=4.0.2
Downloading async_timeout-4.0.2-py3-none-any.whl (5.8 kB)
Collecting packaging>=20.4
Downloading packaging-21.3-py3-none-any.whl (40 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40.8/40.8 kB 1.9 MB/s eta 0:00:00
Collecting wrapt<2,>=1.10
Downloading wrapt-1.14.1-cp310-cp310-win_amd64.whl (35 kB)
Collecting pyparsing!=3.0.5,>=2.0.2
Downloading pyparsing-3.0.9-py3-none-any.whl (98 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 98.3/98.3 kB 624.8 kB/s eta 0:00:00
Installing collected packages: wrapt, pyparsing, async-timeout, packaging, deprecated, redis
Successfully installed async-timeout-4.0.2 deprecated-1.2.13 packaging-21.3 pyparsing-3.0.9 redis-4.3.4 wrapt-1.14.1
因此,redis 包使用 wrapt、pyparsing、async-timeout、打包和不推荐使用的模块来为其模块提供支持。
要使用 redis 包,我们需要导入它。
import redis
进入正题,我们可以使用redis模块提供的keys()方法来访问并获取其中的所有key。
key() 方法从给定的 Redis 数据库返回一个与在其参数中传递的模式相匹配的键列表。 如果不传递任何参数,则有一个默认模式,即*,表示所有键。
为了展示工作中的方法,我们使用 +Key 按钮或以下代码手动预填充了别名 Temp 和一些键的 redis 数据库。
import redis
redisHost = 'localhost'
redisPort = 6379
redisDecodeRes = True
r = redis.StrictRedis(
host=redisHost,
port=redisPort,
decode_responses=redisDecodeRes
)
r.set("ConnectionPool", "Ox1212af34w3141")
上面的代码导致键 ConnectionPool 被添加到具有相应值的 Temp 数据库中。
set() 方法将键值对应用于数据库,而 StrictRedis() 方法创建一个 Redis 连接对象,使我们能够访问数据库。
要通过 GUI 显示数据库(使用别名 Temp)及其密钥,我们可以使用 RedisInsight 应用程序,如图所示。
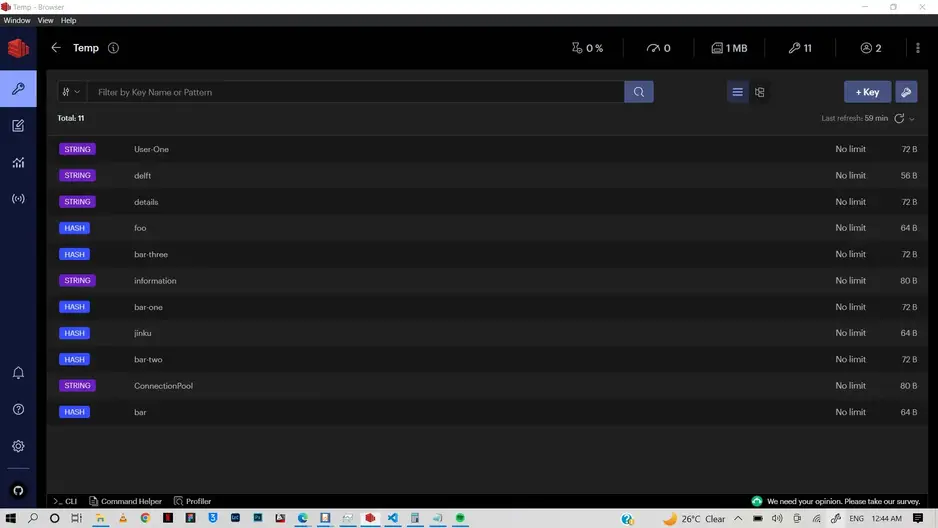
手动向数据库中添加了 11 个密钥以测试 key() 方法。
现在,对于 key() 方法,我们必须使用 StrictRedis() 方法创建一个 Redis 连接对象来访问键。 host、port 和 decode_responses 参数被传递来定义连接的参数。
host 和 port 定义主机名和端口号,decode_responses 定义将传递的数据解码为我们可以轻松使用的 Python 字符串。 keys() 方法然后访问所有可用的键,因为没有传递任何参数。
import redis
redisHost = 'localhost'
redisPort = 6379
redisDecodeRes = True
r = redis.StrictRedis(
host=redisHost,
port=redisPort,
decode_responses=redisDecodeRes,
db=0
)
print(r.keys())
输出:
['bar-two', 'information', 'bar-one', 'details', 'foo', 'jinku', 'bar', 'User-One', 'delft', 'bar-three', 'ConnectionPool']
我们在 Temp 数据库中有一个所有键的列表,我们可以使用它。
如果我们有所需的键模式,我们可以将其作为参数传递。 让我们列出所有以 bar 开头的键。
print(r.keys(pattern="bar*"))
输出:
['bar-two', 'bar-one', 'bar', 'bar-three']
使用 scan_iter() 获取 Redis 数据库中的所有键
对于大型数据库,scan_iter() 允许我们在 Python 应用程序中更好地管理数据。 此外,key() 方法会阻塞服务器并阻止其他使用操作,而对于 scan_iter(),其基于批处理的操作允许其他使用操作。
尽管 keys() 可能更快,但它对于多个基于请求的系统来说并不是很好。
现在,让我们看看它的实际效果。
import redis
redisHost = 'localhost'
redisPort = 6379
redisDecodeRes = True
try:
r = redis.StrictRedis(
host=redisHost,
port=redisPort,
decode_responses=redisDecodeRes,
db=0
)
for key in r.scan_iter(match="bar*"):
print(key)
except Exception as e:
print(e)
输出:
bar-three
bar-one
bar-two
bar
当我们尝试使用数据库时,使用 try/except 有助于处理连接问题。 使用 StrictRedis() 连接后,我们使用 match 参数来定义我们正在寻找的键模式,并循环遍历结果以给出键。
使用 zip_longest 获取 Redis 数据库中的所有键
正如我们所说,对于具有大量键的大型数据库,scan_iter() 方法更好,但我们可以通过按指定数量的批次检索键来进一步改进它,以更好地管理结果。
要创建批处理,我们需要 itertools 模块,它提供可用于不同情况的不同迭代器(或方法)。 在 itertools 模块中,我们有 zip_longest 方法,它返回一个 zip_longest 对象,其 .next() 方法返回一个元组并聚合传递给它的 iterable 中的元素。
我们可以使用 zip_longest() 方法创建一个函数,该函数根据传递的参数创建一批指定数量的键。 比如我们创建一批2,可以用于很多情况。
import redis
from itertools import zip_longest
redisHost = 'localhost'
redisPort = 6379
redisDecodeRes = True
try:
r = redis.StrictRedis(
host=redisHost,
port=redisPort,
decode_responses=redisDecodeRes,
db=0
)
def batch(iterable, num):
initIter = [iter(iterable)] * num
return zip_longest(*initIter)
for keyBatch in batch(r.scan_iter('bar*'), 2):
print(keyBatch)
except Exception as e:
print(e)
输出:
('bar-three', 'bar-one')
('bar-two', 'bar')
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

