Python 中的数据类继承
3.7 版及更高版本在 Python 中引入了数据类继承。 本文广泛解释了多级继承以及如何在 Python 中使用数据类继承。
Python 中的继承
Python中的数据类继承用于从父类中获取子类中的数据,有助于减少重复代码,使代码可重用。
让我们看一个继承的例子:
该程序导入数据类库包以允许创建装饰类。 这里创建的第一个类是Parent,它有两个成员方法——字符串 name 和整数 age。
然后在这里创建一个Parent的子类。 Child 类引入了一个新的成员方法——school。
为类 Parent 创建了一个实例对象 jack,它将两个参数传递给该类。 另一个实例对象 jack_son 是为 Child 类创建的。
由于 Child 类是 Parent 的子类,因此可以在 Child 类中派生数据成员。 这是 Python 中数据类继承的主要特点。
从数据类导入数据类
@dataclass
class Parent:
name: str
age: int
def print_name(self):
print(f"Name is '{self.name}' and age is= {self.age}")
@dataclass
class Child(Parent):
school: str
jack = Parent('Jack snr', 35)
jack_son = Child('Jack jnr', 12, school='havard')
jack_son.print_name()
输出:
C:\python38\python.exe "C:/Users/Win 10/PycharmProjects/class inheritance/2.py"
Name is 'Jack jnr' and age is= 12
Process finished with exit code 0
Python 中的多级继承
正如我们已经了解了 Python 中的数据类继承是如何工作的,我们现在将看看多级继承的概念。 它是一种继承类型,其中从父类创建的子类用作后续孙类的父类。
下面的示例以简单的形式演示了多级继承:
父类
类 Parent 是使用构造函数 __init__ 和成员方法 - print_method 创建的。 构造函数打印语句“Initialized in Parent”,以便在从其子类调用该类时显示该语句。
print_method 函数有一个参数 b,它会在调用此方法时打印出来。
子类
Child 类派生自 Parent 并在其构造函数中打印一条语句。 super().__init__ 引用带有子类的基类。
我们使用 super() 以便子类使用的任何潜在的合作多重继承将调用方法解析顺序 (MRO) 中适当的下一个父类函数。
重载成员方法print_method,一条print语句打印b的值。 在这里,super() 也是指其父类的成员方法。
Grand 子类
此时,程序只是对结构进行样板(重复代码)以创建另一个从 Child 类继承的类。 在 print_method 内部,b 的值使用 super() 递增。
Main 函数
最后,创建了 main 函数,它创建了一个对象 ob 并成为 GrandChild() 的一个实例。 最后,对象 ob 调用 print_method。
Python中使用数据类继承时,多层类就是这样堆叠起来的。
class Parent:
def __init__(self):
print("Initialized in Parent")
def print_method(self, b):
print("Printing from class Parent:", b)
class Child(Parent):
def __init__(self):
print("Initialized in Child")
super().__init__()
def print_method(self, b):
print("Printing from class Child:", b)
super().print_method(b + 1)
class GrandChild(Child):
def __init__(self):
print("Initialized in Grand Child")
super().__init__()
def print_method(self, b):
print("Printing from class Grand Child:", b)
super().print_method(b + 1)
if __name__ == '__main__':
ob = GrandChild()
ob.print_method(10)
输出:
C:\python38\python.exe "C:/Users/Win 10/PycharmProjects/class inheritance/3.py"
Initialized in Grand Child
Initialized in Child
Initialized in Parent
Printing from class Grand Child: 10
Printing from class Child: 11
Printing from class Parent: 12
Process finished with exit code 0
让我们了解代码在这里的作用:
main 函数将值 10 传递给 Grand Child 类的 print_method 函数。 根据 MRO(方法解析顺序),程序首先执行 Grand Child 类,打印 init 语句,然后转到其父类 - Child 类。
Child 类和 Parent 类按照 MRO 打印它们的 init 语句,然后编译器返回到 GrandChild 类的 print_method。 此方法打印 10(b 的值),然后使用 super() 来增加其超类(子类)中 b 的值。
然后编译器继续使用 Child 类的 print_method 并打印 11。然后,在 MRO 的最后一层是打印 12 的 Parent 类。
程序退出,因为父类上不存在超类。
正如我们已经了解了 Python 中的数据类继承中的多级继承是如何工作的,下一节将介绍从父类继承属性的概念以及如何修改它。
在 Python 中使用数据类继承在基类和子类之间混合默认和非默认属性
我们已经了解了如何在 Python 的数据类继承中使用子类访问其父类的数据成员,以及多级继承的工作原理。 现在,一个问题出现了,如果一个子类可以访问它的超类的数据成员,它可以对其进行更改吗?
答案是肯定的,但是一定要避免TypeErrors。 例如,在下面的程序中,有两个类,一个父类和一个子类子类。
Parent 类有三个数据成员——name、age 和一个默认设置为 False 的 bool 变量 ugly。 三个成员方法打印姓名、年龄和 ID。
现在,在派生自 Parent 的修饰的 Child 类中,引入了一个新的数据成员 - school。 通过它,该类将变量 ugly 的属性从 False 更改为 True。
创建了两个对象,Parent 的 jack 和 Child 的 jack_son。 这些对象将参数传递给它们的类,并且两个对象都调用 print_id 方法并打印详细信息。
使用此方法更改基类的默认值的一个主要问题是它会导致 TypeError。
from dataclasses import dataclass
@dataclass
class Parent:
name: str
age: int
ugly: bool = False
def print_name(self):
print(self.name)
def print_age(self):
print(self.age)
def print_id(self):
print(f"ID: Name - {self.name}, age = {self.age}")
@dataclass
class Child(Parent):
school: str
ugly: bool = True
jack = Parent('jack snr', 32, ugly=True)
jack_son = Child('Mathew', 14, school = 'cambridge', ugly=True)
jack.print_id()
jack_son.print_id()
输出:
raise TypeError(f'non-default argument {f.name!r} '
TypeError: non-default argument 'school' follows default argument
此错误背后的原因是,在 Python 的数据类继承中,由于数据类混合属性的方式,属性不能在基类中与默认值一起使用,然后在没有默认值(位置属性)的情况下在子类中使用。
这是因为属性从 MRO 的底部开始合并,并按第一次看到的顺序构建一个有序的属性列表,覆盖保留在它们的原始位置。
默认为 ugly ,Parent 以 name、age和 ugly 开始,然后子级在该列表的末尾添加学校(列表中已经有丑陋)。
这导致列表中包含name、age、ugly 和 school,并且由于school没有默认值,因此 __init__ 函数将结果列为不正确的参数。
当 @dataclass 装饰器创建一个新的数据类时,它会以反向 MRO(从对象开始)搜索该类的所有基类,并将每个基类的字段添加到它找到的每个数据类的字段的有序映射中。
然后,在添加所有基类字段后,它将其字段添加到有序映射中。 所有创建的方法都将使用这种组合计算的有序字段映射。
由于字段的排列,派生类取代了基类。
如果一个没有默认值的字段跟在一个有默认值的字段之后,就会产生一个 TypeError。 无论它发生在单个类中还是由于类继承,都是如此。
解决此问题的第一个替代方法是使用不同的基类将具有默认值的字段强制置于 MRO 订单中的较晚位置。 不惜一切代价避免直接在将用作基类的类(如 Parent)上设置字段。
这个程序有带字段的基类,没有默认值的字段是分开的。 公共类派生自 base-with 和 base-without 类。
公共类的子类将基类放在前面。
from dataclasses import dataclass
@dataclass
class _ParentBase:
name: str
age: int
@dataclass
class _ParentDefaultsBase:
ugly: bool = False
@dataclass
class _ChildBase(_ParentBase):
school: str
@dataclass
class _ChildDefaultsBase(_ParentDefaultsBase):
ugly: bool = True
@dataclass
class Parent(_ParentDefaultsBase, _ParentBase):
def print_name(self):
print(self.name)
def print_age(self):
print(self.age)
def print_id(self):
print(f"ID: Name - {self.name}, age = {self.age}")
@dataclass
class Child(_ChildDefaultsBase, Parent, _ChildBase):
pass
Amit = Parent('Amit snr', 32, ugly=True)
Amit_son = Child('Amit jnr', 12, school='iit', ugly=True)
Amit.print_id()
Amit_son.print_id()
输出:
C:\python38\python.exe "C:/main.py"
The Name is Amit snr and Amit snr is 32 year old
The Name is Amit jnr and Amit jnr is 12 year old
Process finished with exit code 0
此处创建的 MRO 将没有默认值的字段优先于具有默认值的字段,方法是将字段拆分为具有默认值和默认值的字段的基类,并仔细选择继承顺序。 孩子的 MRO 是:
<class 'object'>
||
<class '__main__._ParentBase'>,
||
<class '__main__._ChildBase'>
||
<class '__main__._ParentDefaultsBase'>,
||
<class '__main__.Parent'>,
||
<class '__main__._ChildDefaultsBase'>,
||
<class '__main__._Child'>
尽管 Parent 没有创建任何新字段,但它继承了 ParentDefaultsBase 的字段,并且不应在字段列表顺序中排在最后。 因此,ChildDefaultsBase 最后被保留以完成正确的订单类型。
数据类规则也得到满足,因为类 ParentBase 和 ChildBase(具有没有默认值的字段)出现在 ParentDefaultsBase 和 ChildDefaultsBase(具有具有默认值的字段)之前。
因此,Child 仍然是 Parent 的子类,而 Parent 和 Child 类具有正确的字段顺序:
__ Program Above __
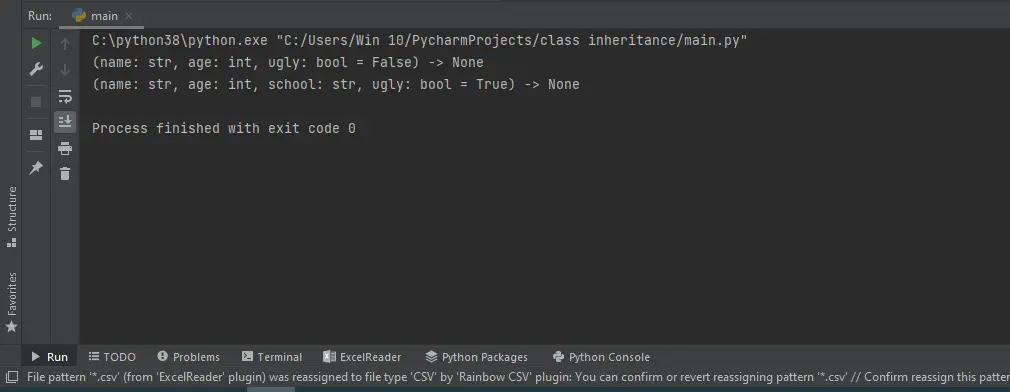
print(signature(Parent))
print(signature(Child))
输出:
总结
本文详细解释了 Python 中的数据类继承。 详细解释了数据类、子类、多级继承以及从基类到子类的混合属性等概念。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

