Python 逐步回归
本篇文章将讨论在 Python 中执行逐步回归的方法。
Python 中的逐步回归
逐步回归是一种用于统计和机器学习的方法,用于选择特征子集来构建线性回归模型。 逐步回归旨在最小化模型的复杂性,同时保持高精度水平。
这种方法在特征数量很多且不清楚哪些特征对预测很重要的情况下特别有用。
使用 Python 中的 statsmodels 库进行逐步回归
statsmodels 库提供了可用于执行逐步回归的 OLS() 类。 此函数使用前向选择和后向消除的组合来选择最佳特征子集。
该函数从一个空模型开始,并根据其系数的显着性逐个添加变量。 不显着的变量从模型中剔除。
这是一个如何在 statsmodels 中使用逐步函数的示例。
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Perform stepwise regression
result = sm.OLS(y, x).fit()
# Print the summary of the model
print(result.summary())
输出:
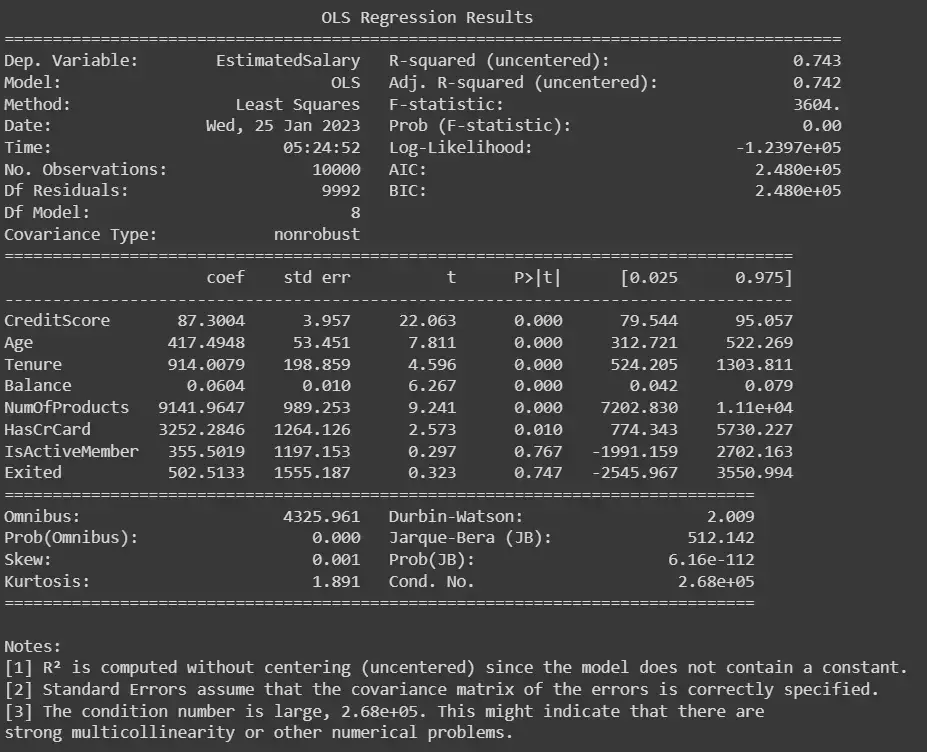
我们首先在上面的代码示例中加载数据并定义因变量和自变量。 然后,我们使用 statsmodels.formula.api 库中的 OLS() 函数执行逐步回归并打印模型摘要,其中包括变量系数、p 值和 R 平方值等信息。
使用 Python 中的 sklearn 库进行逐步回归
sklearn 库提供了一个 RFE(递归特征消除)类来执行逐步回归。 该方法从所有特征开始,并根据重要性递归地消除特征。
RFE 方法使用指定的估计器(例如线性回归模型)来估计特征的重要性,并在每次迭代时递归地删除最不重要的特征。
下面是如何在 sklearn 中使用 RFE 方法的示例。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the RFE object and specify the number of
selector = RFE(estimator, n_features_to_select=5)
# Fit the RFE object to the data
selector = selector.fit(x, y)
# Print the selected features
print(x.columns[selector.support_])
输出:
Index(['Tenure', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'Exited'], dtype='object')
我们首先在上面的代码示例中加载数据并定义因变量和自变量。 然后,我们创建一个线性回归估计器和一个 RFE 对象。
我们将要选择的特征数设置为 5,这意味着最终模型将根据重要性仅包括前 5 个特征。 接下来,我们将 RFE 对象与数据相匹配并打印所选特征。
值得注意的是,RFE() 方法使用指定的估计器来计算特征的重要性,因此对数据使用适当的估计器很重要。 RFE 方法也可以与其他估计器一起使用,例如随机森林或 SVM。
使用 Python 中的 mlxtend 库进行逐步回归
mlxtend 库提供了用于执行逐步回归的 SFS 类。 此函数使用前向选择和后向消除的组合来选择最佳特征子集。
这个函数也是从一个空模型开始,根据变量系数的显着性逐一添加变量。 不显着的变量从模型中剔除。
下面是一个如何在 mlxtend 中使用 stepwise 函数的例子。
import joblib
import sys
sys.modules['sklearn.externals.joblib'] = joblib
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the SFS object and specify the number of features to select
sfs = SFS(estimator, k_features=5, forward=True, floating=False, scoring='r2', cv=5)
# Fit the SFS object to the data
sfs = sfs.fit(x, y)
# Print the selected features
print(sfs.k_feature_idx_)
输出:
(1, 2, 4, 6, 7)
我们首先在此示例中加载数据并定义因变量和自变量。 然后,我们创建一个线性回归估计器和一个 SFS 对象。
我们将要选择的特征数设置为 5,这意味着最终模型将根据重要性仅包括前 5 个特征。 接下来,我们将 SFS 对象与数据相匹配并打印所选特征。
值得注意的是,mlxtend 的 stepwise() 函数使用指定的估计器来计算特征的重要性,因此对数据使用适当的估计器很重要。 该函数还允许我们设置选择过程的方向、评分指标和要使用的交叉验证折叠数。
总之,逐步回归是一种用于线性回归模型中特征选择的强大技术。 statsmodels、sklearn 和 mlxtend 库提供了在 Python 中执行逐步回归的不同方法,每种方法各有优缺点。
方法的选择将取决于问题的具体要求和数据的可用性。 重要的是要注意逐步回归可能容易过度拟合,建议将其与其他特征选择技术和交叉验证结合使用。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

