Python 修复共享内存问题和锁定共享资源问题
本篇文章解释了多处理共享内存的不同方面,并演示了如何使用共享内存解决问题。 我们还将学习如何使用锁来锁定 Python 中的共享资源。
使用 multiprocessing.Array() 在 Python 中使用共享内存
当您有多个子进程时,多处理最关键的方面之一是在进程之间共享数据。
您使用处理模块的能力创建的子进程的基本属性之一是它们独立运行并拥有自己的内存空间。
这意味着孩子的进程将有一些内存空间。 并且,任何变量试图在其自己的内存空间中创建或将被更改,而不是在其父级的内存空间中。
让我们通过一个例子来尝试理解这个概念,并通过导入多处理模块进入代码。
我们创建了一个名为 RESULT 的空列表,并定义了一个名为 Make_Sqaured_List() 的函数,该函数对给定列表的元素进行平方并将它们附加到我们的全局 RESULT 列表中。
Procc_1 对象等于 Process() 类,并将目标设置为不带括号的 Make_Sqaured_List 函数。
并且,对于 args 参数,我们传递一个名为 Items_list 的单独列表,该列表将作为参数提供给 Make_Sqaured_List() 函数。
示例代码:
import multiprocessing
RESULT = []
def Make_Sqaured_List(Num_List):
global RESULT
for n in Num_List:
RESULT.append(n **2)
print(f"Result: {RESULT}")
if __name__ == '__main__':
Items_list = [5,6,7,8]
Procc_1 = multiprocessing.Process(target=Make_Sqaured_List, args=(Items_list,))
Procc_1.start()
Procc_1.join()
让我们执行这个子进程,我们根据我们的子进程得到的结果是全局列表的值。
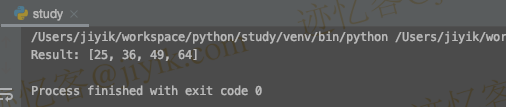
但是,如果我们尝试打印仍然为空的 RESULT 列表,那么 RESULT 列表会发生什么情况?
print(RESULT)
输出:
[]
从我们的主进程来看,我们的父进程还是空的,而从子进程来看,RESULT列表是有内容的。 这只是意味着我们的不同进程都有不同的内存空间。
我们可以通过一个场景来理解这一点,在这个场景中我们有一个进程,这是我们的主程序,我们最初有一个空的 RESULT 列表。
而且,当我们创建一个子进程时,它最初也是一个空的,然后执行 Make_Sqaured_List() 函数,因此 RESULT 列表包含一些项目。 但是,由于我们正在从该内存空间中的父进程访问 RESULT,因此更改是不可见的。
示例代码:
import multiprocessing
RESULT = []
def Make_Sqaured_List(Num_List):
global RESULT
for n in Num_List:
RESULT.append(n **2)
print(f"Result: {RESULT}")
if __name__ == '__main__':
Items_list = [5,6,7,8]
Procc_1 = multiprocessing.Process(target=Make_Sqaured_List, args=(Items_list,))
Procc_1.start()
Procc_1.join()
print(RESULT)
输出:
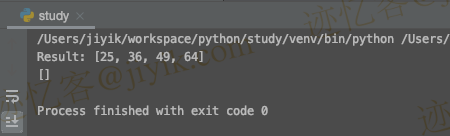
那么,解决这个问题的方法是什么? 但是,首先,让我们看看如何解决它。
解决多进程之间共享数据问题的解决方案
在本节中,我们将看到帮助我们获取任何更改的值并解决多进程之间共享数据问题的解决方案。
该解决方案称为共享内存。 多处理模块为我们提供了两种类型的对象,称为数组和值,可用于在进程之间共享数据。
Array是从共享内存中分配的数组; 基本上,您的计算机内存中有一部分我们可以称为共享内存或多个进程可以访问的区域。
因此,在该共享内存中,我们创建了一个新数组或一个新值。 这些附加值不是我们的基本 Python 数据结构; multiprocessing 模块本身有一些不同和定义的东西。
现在我们使用 multiprocessing.Array() 声明一个名为 RESULT_ARRAY 的对象。 然后,在这个数组中,我们必须传递数据类型。 我们将 i 作为字符串传递,这意味着我们将在其中放入整数值,并且我们必须给出大小。
示例代码:
RESULT_ARRAY= multiprocessing.Array('i', 4)
它与 C 编程风格的数组有关,因此我们可以同时给出大小。 这样,我们就可以将对象存储在所需的位置。
现在我们正在创建一个名为 OBJ_Sum 的新值,它等于 multiprocessing.Value(),它将存储并输入该值。
示例代码:
OBJ_Sum = multiprocessing.Value('i')
接下来,我们将创建一个名为 procc_1 的对象,它将等于 multiprocessing.Process(),我们将调用一个函数。 我们创建了一个名为 Make_Sqaured_List() 的函数,它将采用三个参数:
- list
- array 对象
- value 对象。
我们将使用名为 args 的 Process 参数将这三个参数传递给我们的函数。 例如,看看下面的代码片段。
示例代码:
Procc_1 = multiprocessing.Process(target=Make_Sqaured_List, args=(Items_list, RESULT_ARRAY, OBJ_Sum))
现在在 Make_Sqaured_List() 函数中,我们将使用 enumerate() 函数迭代 Items_list。 这样我们就可以得到Items_list的索引和值了。
它是一个 C 风格的数组,所以我们必须使用索引将值分配给我们的数组。 我们还将对数组的值求和,OBJ_Sum.value 是 multiprocessing.Value() 的一个属性。
示例代码:
def Make_Sqaured_List(Items_list, RESULT, OBJ_Sum):
for i, n in enumerate(Items_list):
RESULT[i] = n **2
OBJ_Sum.value = sum(RESULT)
我们在主进程中定义了一些变量,改变了子进程调用的函数。 所以我们的主要议程是我们是否可以在我们的主要流程中获得那些改变的价值。
现在我们可以访问反映在子进程中的数组并使用 OBJ_Sum.value 获取其总和。 例如,请参见以下代码片段。
示例代码:
import multiprocessing
def Make_Sqaured_List(Items_list, RESULT, OBJ_Sum):
for i, n in enumerate(Items_list):
RESULT[i] = n **2
OBJ_Sum.value = sum(RESULT)
if __name__ == '__main__':
Items_list = [5,6,7,8]
RESULT_ARRAY= multiprocessing.Array('i', 4)
OBJ_Sum = multiprocessing.Value('i')
Procc_1 = multiprocessing.Process(target=Make_Sqaured_List, args=(Items_list, RESULT_ARRAY, OBJ_Sum))
Procc_1.start()
Procc_1.join()
print(RESULT_ARRAY[:])
print(OBJ_Sum.value)
输出:
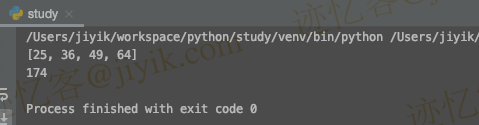
这样,我们可以对父进程中定义的对象以及我们从子进程返回的那些更改进行任何更改。 这可以通过使用共享内存技术来实现。
使用 multiprocessing.Lock() 锁定 Python 中的共享资源
我们将讨论一个名为锁的重要主题; 现在,如果您上过计算机科学或操作系统课程,那么您已经了解了锁。 但是,当涉及到多处理和操作系统概念时,锁是一个关键概念。
首先,让我们考虑一下现实生活中为什么需要锁; 在我们的日常生活中,有些资源不能被两个人同时访问。
例如,浴室的门有锁,因为如果两个人同时试图打开它,就会造成相当尴尬的局面。 这就是我们保护浴室的原因,这是一个带锁的共享资源。
同样,在编程世界中,每当两个进程或线程试图访问一个共享资源,例如共享内存文件或数据库时。 它会产生问题,因此您必须使用锁来保护该访问。
如果我们不将这种保护添加到我们的程序中会发生什么,我们将通过运行示例来了解。 同样,这是一个银行软件程序,这里有两个进程。
第一个过程是使用 MONEY_DP() 函数将钱存入银行,第二个过程是使用 MONEY_WD() 函数从银行取款。 最后,我们正在打印最终余额。
我们从 MONEY_DP 部分的 200 美元余额开始。 我们存入 100 美元,我们有一个跟踪 100 次的 for 循环,在每次迭代中,它都会将 01 美元添加到我们的银行账户中。
同样,在 MONEY_WD 函数中,我们将相同的循环迭代 100 次,每次都会从我们的银行账户中扣除 1 美元。
示例代码:
import multiprocessing
import time
def MONEY_DP(B):
for i in range(100):
time.sleep(0.01)
B.value = B.value + 1
def MONEY_WD(B):
for i in range(100):
time.sleep(0.01)
B.value = B.value - 1
现在我们正在使用一个名为 value 的共享内存变量,我们已经在上一节中了解过它。 这个 multiprocessing 值是一个共享内存资源,所以让我们看看当我们尝试运行这个程序时会发生什么。
if __name__ == '__main__':
B = multiprocessing.Value('i', 200)
Deposit = multiprocessing.Process(target=MONEY_DP, args=(B,))
Withdrawl = multiprocessing.Process(target=MONEY_WD, args=(B,))
Deposit.start()
Withdrawl.start()
Deposit.join()
Withdrawl.join()
print(B.value)
我们将多次运行它,每次,它只是打印不同的值,但它应该打印 200 美元。
输出:
# execution 1
205
# execution 2
201
# execution 3
193
为什么会这样? 它主要发生在该进程试图读取共享内存中名为 B.value 的变量时。
假设 B.value 有一个 200$ 的值,它会读取它,然后加一,然后它会把同样的东西放回同一个变量中。
由于 B.value 是 200$ 并且它是在操作系统级别执行此加法操作,因此在操作系统级别,它将执行多个流水线指令。
所以我们读取了变量 200; 它被加一,并将 201 分配回 B.value 变量。
示例代码:
B.value = B.value + 1
现在,当它同时执行时,该指令也在 MONEY_WD() 函数中执行。
示例代码:
B.value = B.value - 1
虽然我们是先存后取,但是当进程试图读取B.value时,它仍然是200,因为存入过程还没有写回原来的变量。
而不是在 MONEY_WD 进程中将 B.value 读取为 201,它将读取 B.value 为 200,并且在减少 1 之后,它将有 199。
这就是为什么我们会出现不一致的行为。 首先,让我们使用 Lock 来锁定访问; 现在,我们创建一个名为 lock 的变量,并使用多处理模块来使用 Lock 类。
示例代码:
lock=multiprocessing.Lock()
现在我们将该锁传递给两个进程,在两个进程内,我们将调用 lock.acquire() 来放置锁,然后释放锁,我们将调用 lock.release() 函数。
这些锁函数在访问共享资源时保护代码段,称为临界区。
示例代码:
import multiprocessing
import time
def MONEY_DP(B,lock):
for i in range(100):
time.sleep(0.01)
lock.acquire()
B.value = B.value + 1
lock.release()
def MONEY_WD(B,lock):
for i in range(100):
time.sleep(0.01)
lock.acquire()
B.value = B.value - 1
lock.release()
if __name__ == '__main__':
B = multiprocessing.Value('i', 200)
lock=multiprocessing.Lock()
Deposit = multiprocessing.Process(target=MONEY_DP, args=(B,lock))
Withdrawl = multiprocessing.Process(target=MONEY_WD, args=(B,lock))
Deposit.start()
Withdrawl.start()
Deposit.join()
Withdrawl.join()
print(B.value)
现在,这段代码每次都打印 200。
输出:
200
PS C:\Users\Dell\Desktop\demo> python -u "c:\Users\Dell\Desktop\demo\demo.py"
200
PS C:\Users\Dell\Desktop\demo> python -u "c:\Users\Dell\Desktop\demo\demo.py"
200
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

