在 Django 中作为 GROUP BY 查询
大多数人都熟悉 SQL,并且知道如何使用 GROUP BY 子句编写 SQL 查询以分组获取数据。 使用 GROUP BY 子句,我们可以根据单列或多列值创建一组记录并执行聚合功能。
在本文中,我们假设我们正在处理 Bike 数据库,其中包含 Bike_id、Bike_name、Bike_brand、Bike_color、Bike_bought_date、Is_bike_premium、Bike_price 等。
我们将学习使用 GROUP BY 子句对上述 Bike 数据库执行不同的操作。 此外,我们会先使用 GROUP BY 子句编写 SQL 查询,然后将其转换为 Python,以便读者可以轻松理解并快速学会在 Django 中编写查询。
在 Django 中创建 GROUP BY 查询
假设我们要根据颜色统计自行车的数量。 简单来说,我们想根据颜色制作一组自行车,为此,我们在下面编写了 SQL 查询。
SELECT
Bike_color,
COUNT(Bike_id) AS Total_bikes
FROM
Bike
GROUP BY
Bike_color
作为上述 SQL 查询的输出,我们将得到 2 列。 一个是 Bike_color,另一个是 Total_Bikes,代表特定颜色的自行车数量。
现在,我们将上面的 SQL 查询转换为 Python 代码以获得相同的结果。
from django.db.models import Count
Bike.objects
.values('Bike_color')
.annotate(Total_bikes=Count('Bike_id'))
输出:

-
values()- 它替换了 SQL 查询的 GROUP BY 子句。 无论我们在 SQL 查询中使用 GROUP BY 子句的什么列,我们都必须将其用作 values() 方法的参数。 -
annotate()- annotate() 方法将聚合函数作为参数应用于每个组。
这样,我们就可以根据颜色制作一组自行车,并使用 Python 查询计算相同颜色的自行车的数量。
如果用户在 values() 之前调用 annotate() 函数,它不会将聚合函数应用于组的行,而是整条记录。 因此,请确保您在编写查询时使用的方法的顺序。
对 GROUP BY 查询使用多个聚合
在这里,我们将根据颜色制作一组自行车。 之后,我们将使用 Count() 聚合函数对每种颜色的自行车进行计数,并使用 Min() 聚合函数从每组中获得成本最低的自行车。
SELECT
Bike_color,
COUNT(Bike_id) AS Total_bikes,
MIN(Bike_price) As cheap_bike
FROM
Bike
GROUP BY
Bike_color
下面,我们将上述 SQL 查询转换为 Python 代码。
from django.db.models import Count
from django.db.models import Min
Bike.objects
.values('Bike_color')
.annotate(Total_bikes=Count('Bike_id'), cheap_bike=Min('Bike_price'))
输出:
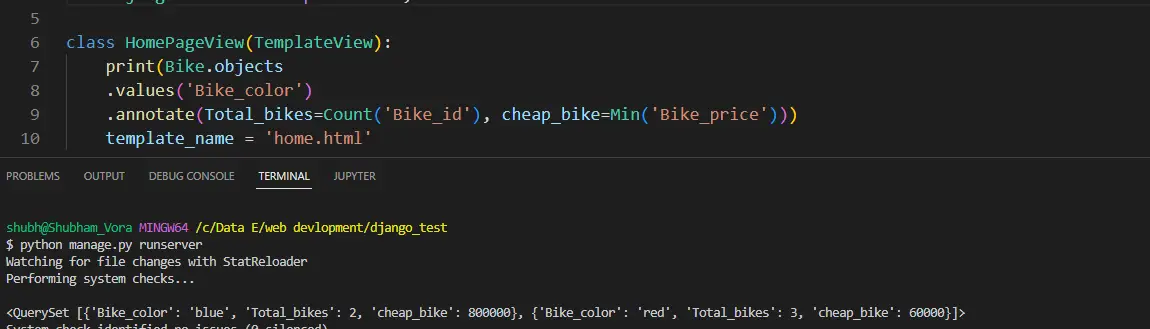
这样,我们就在 Python 中将 Count() 和 Min() 多个聚合函数与 group by 查询一起使用了。
GROUP BY 多列记录
在下面的 SQL 查询中,我们使用了带有 GROUP BY 子句的 Bike_color 和 Is_bike_premium 字段。 查询将根据记录的颜色以及它们是否属于高级类别对记录进行分组。
SELECT
Bike_color,
Is_bike_premium,
COUNT(Bike_id) AS Total_bikes,
FROM
Bike
GROUP BY
Bike_color,
Is_bike_premium
我们必须在 values() 方法中添加多个字段,以将上述 SQL 查询转换为 Python 代码。
from django.db.models import Count
Bike.objects
.values('Bike_color','Is_bike_premium')
.annotate(Total_bikes=Count('Bike_id'))
输出:
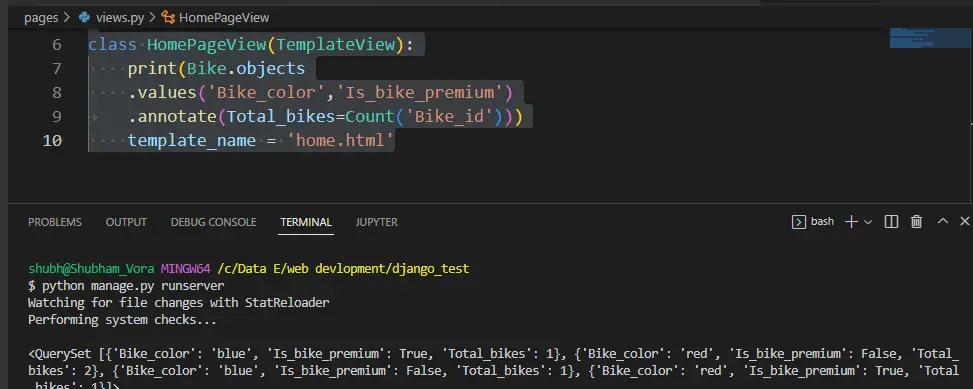
从每个组中过滤记录
在本节中,我们将根据其颜色对 Bike 表的所有记录进行分组,并从每个组中筛选出所有非高级自行车。 简单来说,我们将根据颜色制作一组非高级自行车。
我们在下面的 SQL 查询中使用了 WHERE 子句来过滤自行车。
SELECT
Bike_color,
COUNT(Bike_id) AS Total_bikes
FROM
Bike
WHERE
Is_bike_premium = False
GROUP BY
Bike_color
为了将上述 SQL 查询转换为 Python 代码,我们使用了 Python 的 filter() 方法并将过滤条件作为参数传递。
from django.db.models import Count
Bike.objects
.values('Bike_color')
.filter(Is_bike_premium=False )
.annotate(Total_bikes=Count('Bike_id'))
输出:
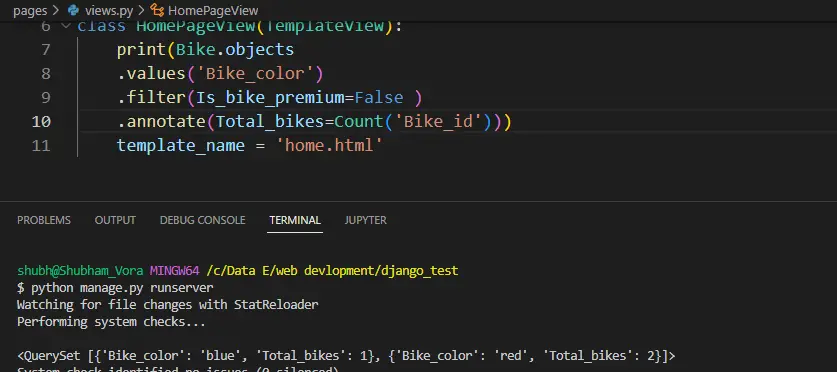
在本文中,我们学习了在 Django 中创建 GROUP BY 查询。 此外,我们还看到了分组查询的不同用例。
此外,用户可以使用 group by 查询和 orderBy() 方法对每个组的记录进行排序。
相关文章
Pandas DataFrame DataFrame.shift() 函数
发布时间:2024/04/24 浏览次数:133 分类:Python
-
DataFrame.shift() 函数是将 DataFrame 的索引按指定的周期数进行移位。
Python pandas.pivot_table() 函数
发布时间:2024/04/24 浏览次数:82 分类:Python
-
Python Pandas pivot_table()函数通过对数据进行汇总,避免了数据的重复。
Pandas read_csv()函数
发布时间:2024/04/24 浏览次数:254 分类:Python
-
Pandas read_csv()函数将指定的逗号分隔值(csv)文件读取到 DataFrame 中。
Pandas 多列合并
发布时间:2024/04/24 浏览次数:628 分类:Python
-
本教程介绍了如何在 Pandas 中使用 DataFrame.merge()方法合并两个 DataFrames。
Pandas loc vs iloc
发布时间:2024/04/24 浏览次数:837 分类:Python
-
本教程介绍了如何使用 Python 中的 loc 和 iloc 从 Pandas DataFrame 中过滤数据。
在 Python 中将 Pandas 系列的日期时间转换为字符串
发布时间:2024/04/24 浏览次数:894 分类:Python
-
了解如何在 Python 中将 Pandas 系列日期时间转换为字符串

