MongoDB 中不区分大小写的查询
在本文中,将简要详细地讨论不区分大小写的查询。 此外,还详细解释了不区分大小写的搜索查询。
本文讨论以下主题。
- 不区分大小写的查询
- 改进不区分大小写的正则表达式查询
-
在
find()方法中使用正则表达式进行不区分大小写的搜索
MongoDB 中不区分大小写的查询
不区分大小写的索引支持在不考虑大小写的情况下比较字符串的搜索。
使用 db.collection.createIndex() 您可以通过将 collation 参数作为可选参数包括在内来建立不区分大小写的索引。
db.collection.createIndex( { "key" : 1 },
{ collation: {
locale : <locale>,
strength : <strength>
}
} )
在为区分大小写的索引指定排序规则时包括以下内容。
- locale - 指定语言规则。
- strength - 用于确定比较规则。 1 或 2 值将指示不区分大小写的排序规则。
行为:
使用不区分大小写的索引不会影响查询结果; 但是,它可以提高速度。
要使用排序规则指定的索引,查询和排序操作必须使用与索引相同的排序规则。 如果一个集合定义了一个排序规则,所有使用该集合的查询和索引都会继承它,除非它们指定了不同的排序规则。
创建不区分大小写的索引
创建带排序规则的索引并将强度选项指定为 1 或 2,以在没有默认排序规则的集合上使用不区分大小写的索引。 要使用索引级排序规则,您必须在查询级别提供相同的排序规则。
以下示例生成一个没有默认排序规则的集合,并向类型列添加一个具有不区分大小写排序规则的索引。
db.createCollection("fruit")
db.fruit.createIndex( { type: 1},
{ collation: { locale: `en`, strength: 2 } } )
查询必须具有相同的排序规则才能使用索引。
db.fruit.insertMany( [
{ type: "bloctak" },
{ type: "Bloctak" },
{ type: "BLOCTAK" }
] )
db.fruit.find( { type: "bloctak" } )
//not use index, finds one result
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 2 } )
// uses index, and will find three results
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 1 } )
//not uses the index, finds three results
使用默认排序规则的集合上的不区分大小写的索引 如果您使用默认排序规则建立集合,则所有未来的索引都会继承该排序规则,除非您提供不同的排序规则。 所有未指定排序规则的查询都继承默认排序规则。
下面的示例生成一个具有默认排序规则的名称集合,然后在 first_name 字段上建立索引。
db.createCollection("names", { collation: { locale: `en_US`, strength: 2 } } )
db.names.createIndex( { first_name: 1 } ) // inherits the default collation
插入一小部分名称:
db.names.insertMany( [
{ first_name: "Betsy" },
{ first_name: "BETSY"},
{ first_name: "betsy"}
] )
默认情况下,对该集合的查询使用提供的排序规则,如果可能,还使用索引。
db.names.find( { first_name: "betsy" } )
// inherits the default collation: { collation: { locale: `en_US`, strength: 2 } }
// finds three results
前面的过程使用集合的默认排序规则发现所有三个文档。 它在 first_name 字段上使用索引以提高效率。
该集合可能仍会通过在查询中指定不同的排序规则来执行区分大小写的搜索。
db.names.find( { first_name: "betsy" } ).collation( { locale: `en_US` } )
// not use the collection`s default collation, finds one result
前面的过程只返回一个文档,因为它使用了一个没有提供强度值的排序规则。 它不使用索引或集合的默认排序规则。
改进不区分大小写的正则表达式查询
如果您经常进行不区分大小写的正则表达式查询(使用 I 选项),您应该建立一个不区分大小写的索引来适应您的搜索。
索引上的排序规则可用于提供特定于语言的字符串比较规则,例如字母大小写和重音符号规则。 不区分大小写的索引显着提高了不区分大小写的查询的性能。
考虑 employees 集合中的以下文档。 除了通常的 _id 索引外,此集合不包含其他索引。
db={
"employees": [
{
"_id": 1,
"first_name": "Hannah",
"last_name": "Simmons",
"dept": "Engineering"
},
{
"_id": 2,
"first_name": "Michael",
"last_name": "Hughes",
"dept": "Security"
},
{
"_id": 3,
"first_name": "Wendy",
"last_name": "Crawford",
"dept": "Human Resources"
},
{
"_id": 4,
"first_name": "MICHAEL",
"last_name": "FLORES",
"dept": "Sales"
}
]
}
如果您的应用程序经常搜索 first_name 列,您可能希望使用不区分大小写的正则表达式查询来发现匹配的名称。
不区分大小写的正则表达式还有助于匹配不同的数据格式,如上例所示,您的 first_name 是 Michael 和 MICHAEL。
如果用户搜索 michael,程序可能会执行以下查询。
db.employees.find({
first_name: {
$regex: "michael",
$options: "i"
}
})
因为此查询包含 $regex:
{ "_id" : 2, "first_name" : "Michael", "last_name" : "Hughes", "dept" : "Security" }
{ "_id" : 4, "first_name" : "MICHAEL", "last_name" : "FLORES", "dept" : "Sales" }
尽管此查询返回所需的文档,但不支持索引的不区分大小写的正则表达式查询速度很慢。 您可以通过在 first_name 字段上创建不区分大小写的索引来提高效率。
db.employees.createIndex(
{ first_name: 1 },
{ collation: { locale: 'en', strength: 2 } }
)
当索引的整理文档的强度字段设置为 1 或 2 时,索引不区分大小写,以便更广泛地解释整理文档和各种强度值。
对于使用该索引的应用程序,您还必须在查询中提及索引的整理文档。 从之前的 db.collection.find() 函数中删除 $regex 运算符,并改用新构造的索引。
db.employees.find( { first_name: "michael" } ).collation( { locale: 'en', strength: 2 } )
在为查询使用不区分大小写的索引时,不要使用 $regex 运算符。 $regex 实现不支持排序规则并且不能使用不区分大小写的索引。
在 find() 方法中使用正则表达式在 MongoDB 中进行不区分大小写的搜索
在 find() 方法中使用正则表达式进行不区分大小写的搜索。
语法:
db.demo572.find({"yourFieldName" : { `$regex`:/^yourValue$/i}});
为了理解上述语法,让我们创建一个文档集合。
> db.demo572.insertOne({"CountryName":"US"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f0e581e9acd78b427f1")
}
> db.demo572.insertOne({"CountryName":"UK"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f17581e9acd78b427f2")
}
> db.demo572.insertOne({"CountryName":"Us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f1b581e9acd78b427f3")
}
> db.demo572.insertOne({"CountryName":"AUS"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f20581e9acd78b427f4")
}
> db.demo572.insertOne({"CountryName":"us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f25581e9acd78b427f5")
}
find() 函数显示集合中的所有文档。
db.demo572.find();
这将产生以下输出。
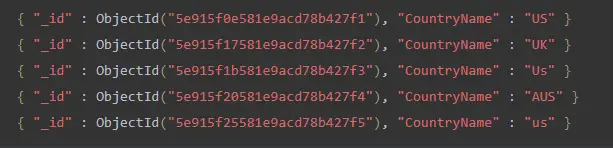
以下是不区分大小写搜索的查询。
> db.demo572.find({"CountryName" : { `$regex`:/^US$/i}});
这将产生以下输出。

相关文章
在 MongoDB Shell 中列出所有数据库
发布时间:2023/05/11 浏览次数:180 分类:MongoDB
-
交互式 Mongo Shell 提供了多个用于获取数据的选项。 本文介绍了在 Mongo Shell 中列出数据库的几种不同方法。
MongoDB 中检查字段包含的字符串
发布时间:2023/05/11 浏览次数:1024 分类:MongoDB
-
这篇文章解决了如何在 MongoDB 中使用正则表达式来确定字段是否包含字符串。在 MongoDB 中使用正则表达式 正则表达式 (regex) 是定义搜索模式的文本字符串。
在 MongoDB 中 upsert 更新插入
发布时间:2023/05/11 浏览次数:214 分类:MongoDB
-
在 MongoDB 中,upsert 结合了更新和插入命令。 它可以在 update() 和 findAndModify() 操作中使用。MongoDB 中的 upsert 查询 upsert 采用单个布尔参数。
如何卸载 MongoDB
发布时间:2023/05/11 浏览次数:745 分类:MongoDB
-
要从您的计算机中卸载 MongoDB,您必须先删除 MongoDB 服务、数据库和日志文件。使用这篇 MongoDB 文章,您将能够从 Ubuntu Linux、Mac 和 Windows 卸载 MongoDB。 请务必保留数据备份,因为一旦卸载,便
在 MongoDB 中存储日期和时间
发布时间:2023/05/11 浏览次数:762 分类:MongoDB
-
本 MongoDB 教程解释了 Date() 对象是什么以及如何使用 Date() 方法对集合进行排序。 这也将帮助您找到在 MongoDB 中显示和存储日期/时间的最佳方法。
MongoDB 按 ID 查找
发布时间:2023/05/11 浏览次数:1856 分类:MongoDB
-
MongoDB 中的 find by Id() 函数用于获取与用户提供的 id 相匹配的文档。 如果找不到与指定 ID 匹配的文档,则返回空值。
检查 MongoDB 服务器是否正在运行
发布时间:2023/05/11 浏览次数:247 分类:MongoDB
-
这篇 MongoDB 教程将告诉您如何检查是否安装了 MongoDB 以及安装的 MongoDB 服务器的版本。 它在 Windows、UBUNTU 和 MAC 等不同的操作系统中实现。
MongoDB 中的分页
发布时间:2023/05/11 浏览次数:174 分类:MongoDB
-
这篇文章将介绍什么是 MongoDB 中的分页。 为什么在 MongoDB 中需要分页以及在 MongoDB 中完成分页的不同方法或方式是什么。
MongoDB 从查询开始
发布时间:2023/05/11 浏览次数:186 分类:MongoDB
-
在这篇 MongoDB 文章中,用户将学习如何使用 $regex 进行开始查询。 它为查询中的模式匹配字符串提供正则表达式功能。

