Java 中拓扑排序的实现
这篇深入的文章将教你如何以递归顺序在有向无环图上实现拓扑排序。本教程分为两个部分。
首先,我们从理论上展开拓扑顺序的结构、应用、范围和排序,以帮助我们的读者建立基础,然后自己执行 Java 代码。
你可能已经猜到了,本文的第二部分是关于有向无环图 (DAG) 的实现。
Java 中的拓扑排序
拓扑排序是图中标注 (n) 的排序。如果在 (u,v) 之间有一条边,那么 u 必须在 v 之前。
在现实世界的场景中,它可以成为构建相互依赖的应用程序的基础。
在我们进行拓扑排序之前,你必须考虑只有有向无环图 (DAG) 才能进行拓扑排序。
拓扑排序的两个真实示例
- 例如,在集成开发环境 (IDE) 中,给定管理用户文件系统的底层逻辑,IDE 可以根据通过 GUI 获取的用户偏好使用拓扑顺序来确定文件的执行和管理。
- 考虑以下示例:两条路线可以将你带到目的地(A 和 B)。
要到达那里,你一次只能带一个。假设你走 B 路。在这种情况下,你不会走 A 路。
因此,它不会创建一个绝对循环。因此,拓扑排序也是可能的。
相反,只有一个周期。拓扑顺序很可能被排除。
拓扑排序的应用
- 根据作业之间的相互依赖安排作业。这种类型的排序在基于研究的应用软件工程、能源效率、云和网络中广泛执行。
- 拓扑排序的另一个应用可以是确定编译任务应该如何在 makefile、数据序列化和链接器中的符号依赖中执行。
- 也适用于制造工作流程和上下文无关语法。
- 很多构建系统都使用这种算法。
- 迁移系统长期以来一直在使用这种顺序。
时间复杂度
它类似于深度优先搜索 (DFS) 算法,但有一个额外的堆栈。时间复杂度一般来说是 O(V+E)。
辅助空间
O(V) - 堆栈需要额外的空间。
直接无环图的演示
首先,你应该清楚,如果图是有向无环图 (DAG),拓扑排序是唯一可行的解决方案。另外,请注意,对于给定的有向无环图,可能有几种替代的拓扑排序。
拓扑排序是顶点在数组中的排列。
考虑以下示例:
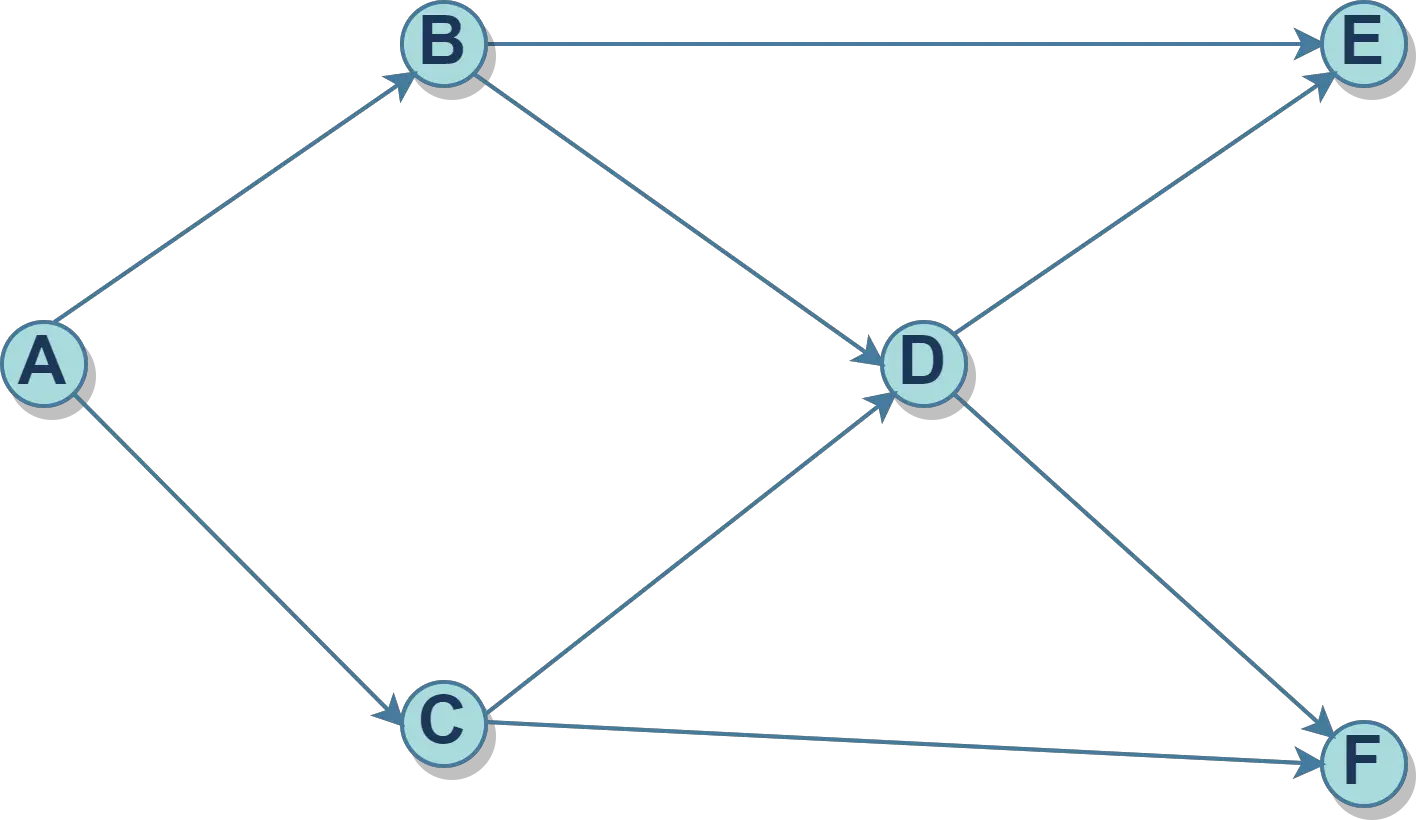
此 DAG 最多有四种可能的排序解决方案:
A B C D E F
A B C D F E
A C B D E F
A C B D F E
如果你理解了缩写,我们希望你也能理解以下对 DAG 的假设描述。值得一提的是,我们的演示只是为了解释通用过程。
如果你对数据结构方面感兴趣,请考虑另一种选择。但是,以下描述足以使用 Java 以递归和迭代顺序对直接图进行排序,以达到所有实际目的。
因此,事不宜迟,请按照以下步骤操作。
-
找到每个图节点的入度(
n):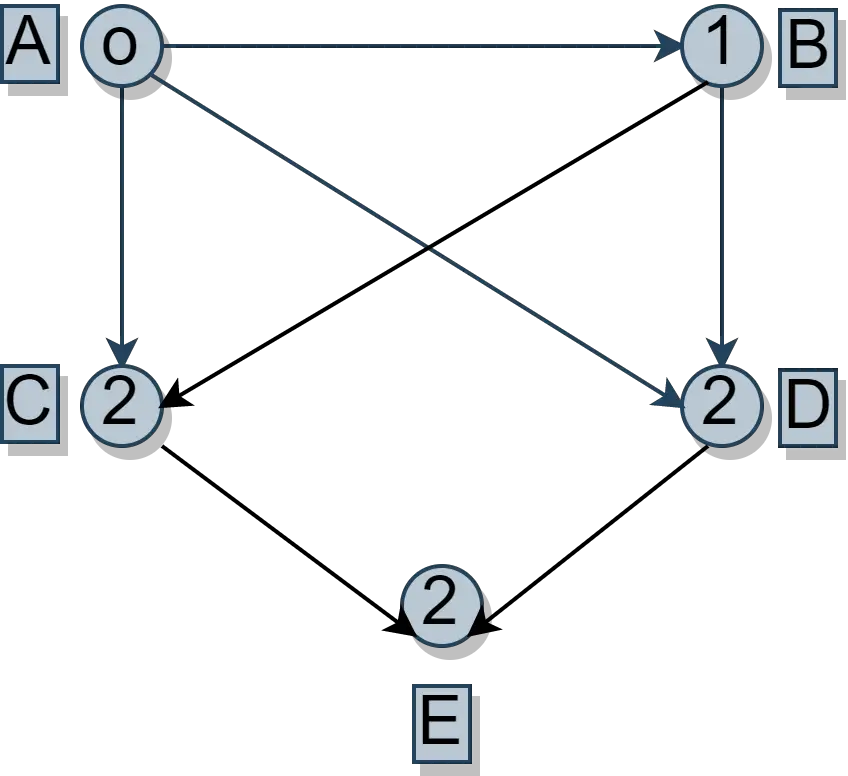
如你所见,
VA在上图中的in-degree最少。 -
因此,现在我们将删除
VA及其相关边。这些相同的边也称为邻居。 -
完成后,你需要做的就是更新其他顶点的
in-degree。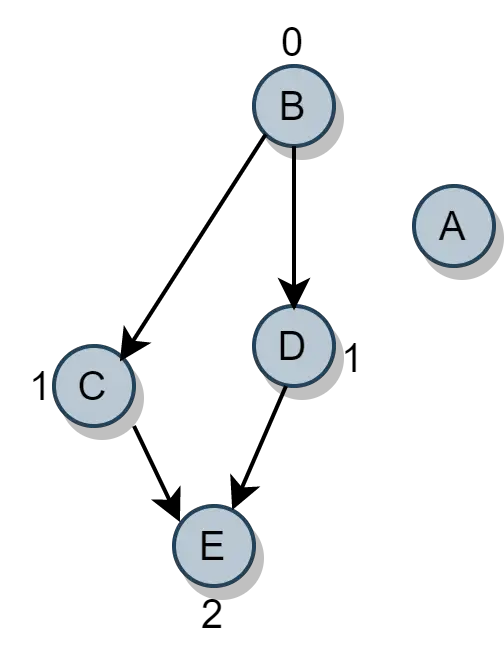
-
VB的in-degree最少。删除VB及其相关边。 -
现在,更新其他顶点的
in-degree。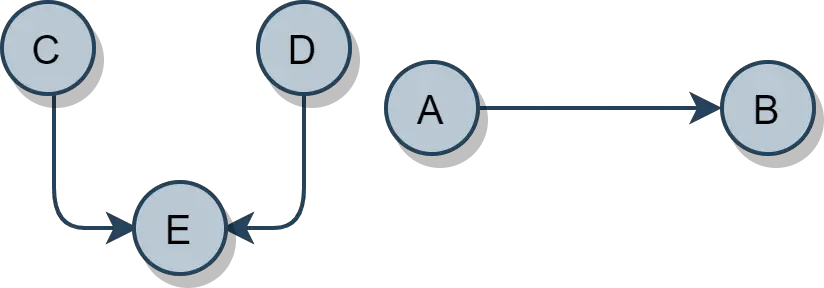
-
上图也可以表示为:
C => 0 , D => 0, E => 2 - 同样,此图的执行也可能有所不同。
- 仅供大家理解演示。
由于我们得到了两个入度最小的顶点,因此最终可以将图排序为以下两个 n 顺序。
A B C D E
A B D C E
Java 中拓扑排序的实现
我们将使用这个图来实现。我们的目标是基于图论确定 u 在 v 之前的从属关系。
不用说,这个执行是基于 DAG 和 DFS。我们将使用一种算法对图进行拓扑排序。
请继续阅读每一步以了解更多信息。
- 图表:
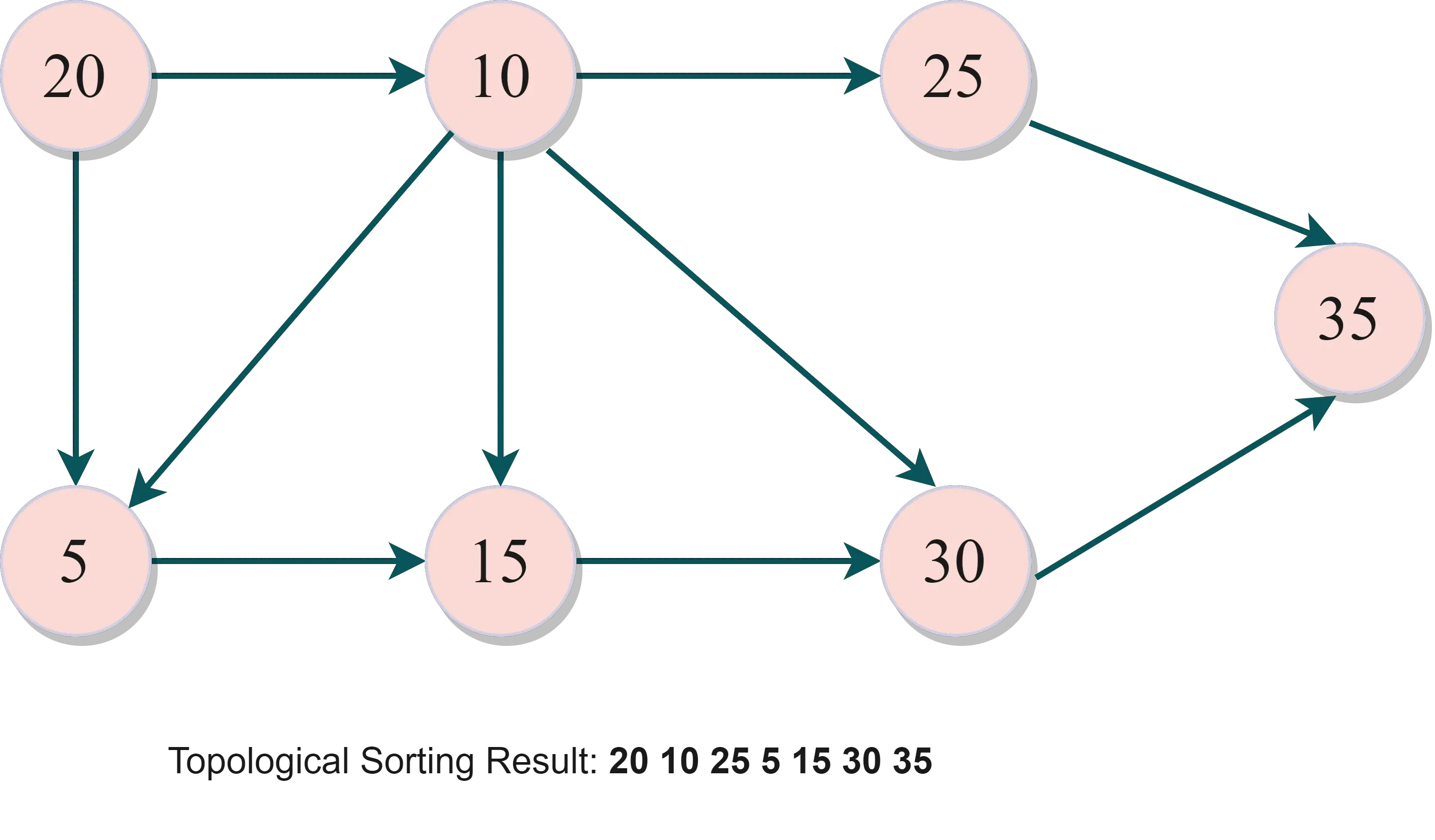
让我们以 v15 为例。V15 取决于 v10 和 v5。
V5 依赖于 v10 和 v20。V10 依赖于 v20。
基于依赖关系,v5、v10 和 v20 在拓扑排序中应该排在 v15 之前。
你还应该了解深度优先搜索 (DFS) 以了解此实现。
- DFS 算法:
深度优先搜索,也称为深度优先遍历,是一种递归算法,用于查找图或树数据结构的所有顶点。遍历一个图需要访问它的所有节点。
它将图形的每个顶点分类为两组之一。
-
访问
v。 -
没有访问
v。
另外,请注意 DFS 算法的功能如下:
- 最初,它将图形的顶点排列在堆栈的顶部。
- 然后,它将堆栈中的顶部项目添加到访问列表中。
- 之后,它会列出与该顶点相邻的节点。
- 将不在访问列表中的堆叠在顶部。
同时,应重复步骤 2 和 3,直到堆栈为空。
Java 中递归顺序的拓扑排序
因为拓扑排序包含一个短栈,所以我们不会立即打印顶点。相反,我们将递归地对其所有邻居调用拓扑排序,然后将其推送到堆栈中。
到目前为止,让我们将逻辑流程分解为几个易于理解的部分。
-
TopoSortDAG类 - 包含一个包含所有节点的堆栈,并确定已访问和未访问的节点。
代码:
public class TopoSortDAG {
Stack<N> customstack;
public TopoSortDAG() {
customstack = new Stack<>();
}
static class N {
int d;
boolean isVstd;
List<N> nghbr;
N(int d) {
this.d = d;
this.nghbr = new ArrayList<>();
}
- 递归拓扑排序算法
代码:
public void tpSort(N N) {
List<N> nghbr = N.getnghbr();
for (int i = 0; i < nghbr.size(); i++) {
N n = nghbr.get(i);
if (n != null && !n.isVstd) {
tpSort(n);
n.isVstd = true;
}
}
customstack.push(N);
}
解释:
-
该算法的执行是因为当我们将一个
v压入堆栈时,我们之前已经压入了它的邻居(及其依赖项)。 -
从此以后,没有依赖关系的
v将自动位于堆栈顶部。
到现在为止,我们希望你已经理解了迄今为止驱动拓扑排序的基本概念。
也就是说,在我们运行整个程序之前,你应该首先了解每个步骤,以便你可以在下次使用 toposort 时创建图表。
使用递归顺序在 Java 中实现拓扑排序:
//We will implement a topological sort algorithm on a direct acyclic graph using the depth-first search technique.
package delftstack.com.util;
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* @author SARWAN
*
*/
public class TopoSortDAG {
Stack<N> customstack;
public TopoSortDAG() {
customstack = new Stack<>();
}
static class N {
int d;
boolean isVstd;
List<N> nghbr;
N(int d) {
this.d = d;
this.nghbr = new ArrayList<>();
}
public void adj(N nghbrN) {
this.nghbr.add(nghbrN);
}
public List<N> getnghbr() {
return nghbr;
}
public void setnghbr(List<N> nghbr) {
this.nghbr = nghbr;
}
public String toString() {
return "" + d;
}
}
public void tpSort(N N) {
List<N> nghbr = N.getnghbr();
for (int i = 0; i < nghbr.size(); i++) {
N n = nghbr.get(i);
if (n != null && !n.isVstd) {
tpSort(n);
n.isVstd = true;
}
}
customstack.push(N);
}
public static void main(String arg[]) {
TopoSortDAG topo = new TopoSortDAG();
N N20 = new N(20);
N N5 = new N(5);
N N10 = new N(10);
N N15 = new N(15);
N N30 = new N(30);
N N25 = new N(25);
N N35 = new N(35);
N20.adj(N5);
N20.adj(N10);
N5.adj(N15);
N10.adj(N5);
N10.adj(N15);
N10.adj(N30);
N10.adj(N25);
N15.adj(N30);
N30.adj(N35);
N25.adj(N35);
System.out.println("Sorting Result Set Based on the Graph:");
topo.tpSort(N20);
Stack<N> reS = topo.customstack;
while (reS.empty() == false)
System.out.print(reS.pop() + " ");
}
}
输出:
Sorting Result Set Based on the Graph:
20 10 25 5 15 30 35
输出堆栈:

相关文章
如何在 Java 中延迟几秒钟的时间
发布时间:2023/12/17 浏览次数:217 分类:Java
-
本篇文章主要介绍如何在 Java 中制造程序延迟。本教程介绍了如何在 Java 中制造程序延时,并列举了一些示例代码来了解它。
如何在 Java 中把 Hashmap 转换为 JSON 对象
发布时间:2023/12/17 浏览次数:187 分类:Java
-
它描述了允许我们将哈希图转换为简单的 JSON 对象的方法。本文介绍了在 Java 中把 Hashmap 转换为 JSON 对象的方法。我们将看到关于创建一个 hashmap,然后将其转换为 JSON 对象的详细例子。
如何在 Java 中按值排序 Map
发布时间:2023/12/17 浏览次数:171 分类:Java
-
本文介绍了如何在 Java 中按值对 Map 进行排序。本教程介绍了如何在 Java 中按值对 Map
如何在 Java 中打印 HashMap
发布时间:2023/12/17 浏览次数:192 分类:Java
-
本帖介绍了如何在 Java 中打印 HashMap。本教程介绍了如何在 Java 中打印 HashMap 元素,还列举了一些示例代码来理解这个主题。
在 Java 中更新 Hashmap 的值
发布时间:2023/12/17 浏览次数:146 分类:Java
-
本文介绍了如何在 Java 中更新 HashMap 中的一个值。本文介绍了如何在 Java 中使用 HashMap 类中包含的两个方法-put() 和 replace() 更新 HashMap 中的值。
Java 中的 hashmap 和 map 之间的区别
发布时间:2023/12/17 浏览次数:79 分类:Java
-
本文介绍了 Java 中的 hashmap 和 map 接口之间的区别。本教程介绍了 Java 中 Map 和 HashMap 之间的主要区别。在 Java 中,Map 是用于以键值对存储数据的接口,
在 Java 中获取用户主目录
发布时间:2023/12/17 浏览次数:218 分类:Java
-
这篇文章向你展示了如何在 Java 中获取用户主目录。本教程介绍了如何在 Java 中获取用户主目录,并列出了一些示例代码以指导你完成该主题。
Java 中 size 和 length 的区别
发布时间:2023/12/17 浏览次数:179 分类:Java
-
这篇文章教你如何知道 Java 中大小和长度之间的区别。本教程介绍了 Java 中大小和长度之间的区别。我们还列出了一些示例代码以帮助你理解该主题。
Java 中的互斥锁
发布时间:2023/12/17 浏览次数:111 分类:Java
-
了解有关 Java 中互斥锁的一切,在计算机科学领域,互斥或互斥被称为并发控制的属性。每台计算机都使用称为线程的最小程序指令序列。有一次,计算机在一个线程上工作。为了更好地理解,

