Unicode 字符集和 UTF-8、UTF-16、UTF-32 编码
ASCII码
在较早的计算时代,ASCII 代码用于表示字符。英语只有 26 个字母和一些其他特殊字符和符号。
下表是 ASCII 码对照表,包含字符及其相应的十进制和十六进制值。
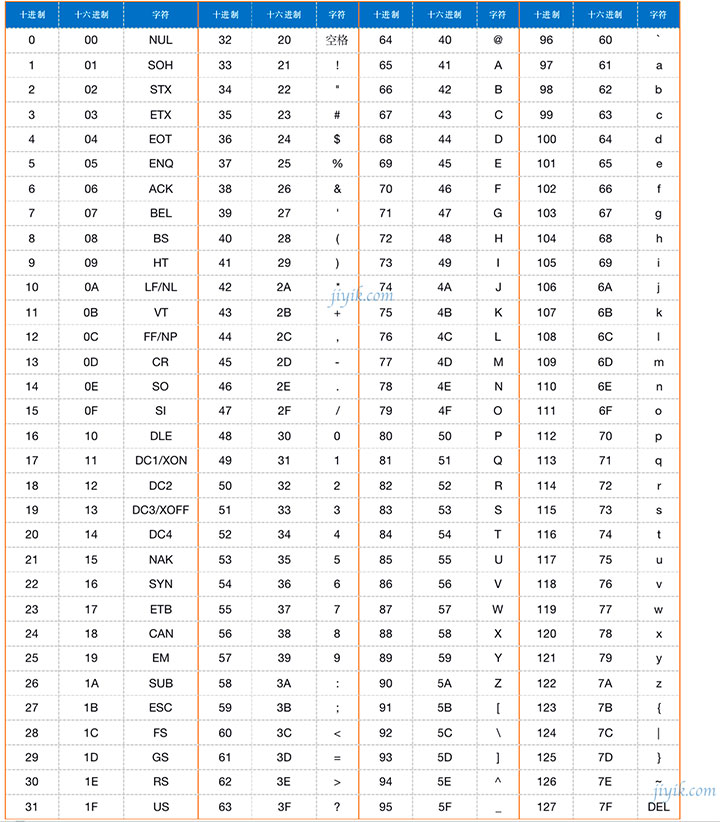
从上表可以推断出,ASCII 值可以在十进制数系统中表示为 0 到 127。让我们看看 0 和 127 在 8 位字节中的二进制表示。
0 表示为
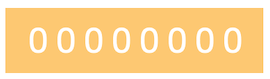
127表示为

从上面的二进制表示可以推断,十进制值 0 到 127 可以使用 7 位来表示,而第 8 位是空闲的。
警告从这个地方起,混乱开始了。
人们想出了不同的方法来使用剩余的第八位,从而使其可以表示从 128 到 255 的十进制值。那么冲突就发生了。例如,越南人使用十进制值 182 来表示越南字母 ờ,而印度人使用相同的值 182 来表示印地语字母घ。因此,如果印度人写的电子邮件包含字母घ并且它被越南人阅读,那么将会显示为ờ。显然这不是预期的效果。
那么如何解决这个问题呢,接下来就该 Unicode 出场了。
Unicode 和代码点
Unicode 字符集将世界上的每个字符都映射到一个唯一的数字上。这确保了不同语言的字母之间没有冲突。这些数字与平台无关。
这些唯一的数字在 unicode 术语中称为代码点。
让我们看看它们是如何被引用的。
使用代码点引用 拉丁字符ṍ
U+1E4D
U+ 表示 unicode,1E4D是分配给字符 ṍ 的十六进制值。
英文字母A表示为 U+0041
好了,了解了这些,接下来该是重头戏了
UTF-8 编码
现在我们知道什么是 unicode 以及如何将世界上的每个字母分配给一个唯一的代码点,我们需要一种在计算机内存中表示这些代码点的方法。这就是字符编码登场的地方。 其中最为人们所熟知的就是 UTF-8 编码。
UTF-8 编码是一种大小可变的编码方案,用于表示内存中的 unicode 代码点。大小可变编码意味着代码点根据其大小使用 1、2、3 或 4 个字节表示。
UTF-8 1 字节编码
1个字节编码的标识是第一个比特位为0。
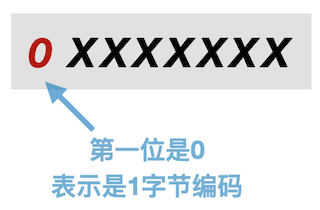
英文字母A的 unicode 代码点为 U+0041。它的二进制表示是1000001。
A 以 UTF-8 编码表示为
红色的0位表示使用1字节编码,其余位代表码位
UTF-8 2 字节编码
代码点为 U+00F1 的拉丁字母ñ的二进制值11110001。该值大于可以使用 1 字节编码格式表示的最大值,因此该字母表将使用 UTF-8 2 字节编码表示。
2 字节编码的方式是由第一个字节比特位中的高三位的比特序列110和第二个字节比特位中的高二位的比特序列10来标识。

Unicode 代码点U+00F1的二进制值是1111 0001。用2字节编码格式填充这些位,我们得到如下所示的ñ的UTF-8 2字节编码表示。
填充是从映射到第二个字节的最低有效位的代码点的最低有效位开始完成的。
蓝色的二进制数字11110001代表码位U+00F1的二进制值,红色的是2字节编码标识符。黑色零用于填充字节中的空位。
UTF-8 3 字节编码
具有代码点U+1E4D的拉丁字符ṍ使用 3 字节编码表示,因为它大于使用 2 字节编码可以表示的最大值。
3 字节编码通过第一个字节中的位序列1110 和第二个和第三个字节中的 10的存在来标识。
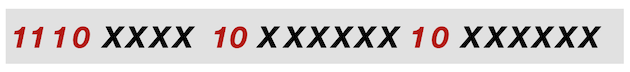
ṍ 十六进制代码点 0x1E4D,对应的二进制值为1111001001101。将这些位填充到上述编码格式中,我们得到了下面所示的 ṍ 的UTF-8 3 字节编码表示。
填充是从映射到第三个字节的最低有效位的代码点的最低有效位开始进行的。
红色位表示 3 字节编码,黑色位是填充位,蓝色位表示代码点。
UTF-8 4 字节编码
表情符号😭的Unicode代码点U+1F62D。这大于可以使用 3 字节编码表示的最大值,因此将使用 4 字节编码表示。
4 字节编码通过第一个字节中的11110和随后的第二个、第三个和第四个字节中的10来标识。

U+1F62D的二进制表示是11111011000101101。将这些位填入上述编码格式,我们就得到了😭的UTF-8 4字节编码。代码点的最低有效位映射到第四个字节的最低有效位,依此类推。
红色位标识4字节编码格式,蓝色位是实际码位,黑色位是填充位。
上面我们分别对 UTF-8 的几种编码方式进行了详细的介绍。接下来我们顺带介绍一下 UTF-16 和 UTF-32 编码方式
UTF-16 编码
UTF-16 编码是一种可变字节编码方案,它使用 2 个字节或 4 个字节来表示 unicode 代码点。所有现代语言的大多数字符都使用 2 个字节表示。
拉丁字母ñ的Unicode代码点为 U+00F1 二进制表示为 11110001 。其 UTF-16 编码表示为
上面的表示是在 Big Endian 字节顺序模式下(最高有效位在前)。
UTF-32 编码
UTF-32 编码是一种固定字节编码方案,它使用 4 个字节来表示所有代码点。
英文字母 A 具有 Unicode 代码点 U+0041。它的二进制表示是 1000001。
它以UTF-32编码表示,如下所示,
蓝色位是代码点的二进制表示。上面的表示是在 Big Endian 字节顺序模式下。
以上就是关于字符集和字符编码的所有内容。
相关文章
使用 JavaScript 编码 HTML
发布时间:2024/03/20 浏览次数:93 分类:JavaScript
-
本教程将教你如何使用不同的方法对 HTML 字符串进行编码。这些方法的共同点是字符串替换,它替换了具有潜在危险的字符。
JavaScript 邮政编码验证
发布时间:2024/03/20 浏览次数:90 分类:JavaScript
-
在本文中,我们将学习如何使用正则表达式来验证邮政编码,使用 JavaScript 代码和不同的示例。
Windows PowerShell 中的 Base64 编码
发布时间:2024/03/04 浏览次数:332 分类:编程语言
-
本文将展示如何编码和解码 base64 字符串。Windows PowerShell 当前版本没有本机命令,因此我们将向你展示如何执行此操作的替代方法。
PowerShell 中的 UTF-8 编码(CHCP 65001)
发布时间:2024/02/29 浏览次数:312 分类:编程语言
-
本教程将介绍在 PowerShell 中使用 UTF-8 编码的不同方法。
在 C# 中对 Base64 字符串进行编码和解码
发布时间:2024/01/16 浏览次数:231 分类:编程语言
-
Convert 类可用于在 C# 中将标准字符串编码为 base64 字符串,并将 base64 字符串解码为标准字符串。使用 C# 中的 Convert.ToBase64String() 方法将字符串编码为 Base64 字符串
C++ 中的 Base 64 编码实现
发布时间:2023/08/25 浏览次数:206 分类:C++
-
本文将讨论 C++ 中的 base_64 编码。首先,我们将讨论 base_64 编码以及需要它的原因和位置。 稍后,我们将讨论 C++ 中的 base_64 编码/解码。
在 PHP 中将图像编码为 Base64
发布时间:2023/03/29 浏览次数:168 分类:PHP
-
本文将教你如何在 PHP 中将图像编码为 base64。你将在 PHP 中使用 pathinfo、file_get_contents、base64_encode 和 mime_content_type 等函数的组合。
在 PHP 中编码 HTML
发布时间:2023/03/29 浏览次数:160 分类:PHP
-
本教程将教你如何在 PHP 中编码 HTML。你将使用 htmlspecialchars()、htmlentities() 和自定义方法。

