Unicode character set and UTF-8, UTF-16, UTF-32 encoding
ASCII Code
In the early days of computing, ASCII codes were used to represent characters. The English language only has 26 letters and a few other special characters and symbols.
The following table is an ASCII code comparison table containing characters and their corresponding decimal and hexadecimal values.
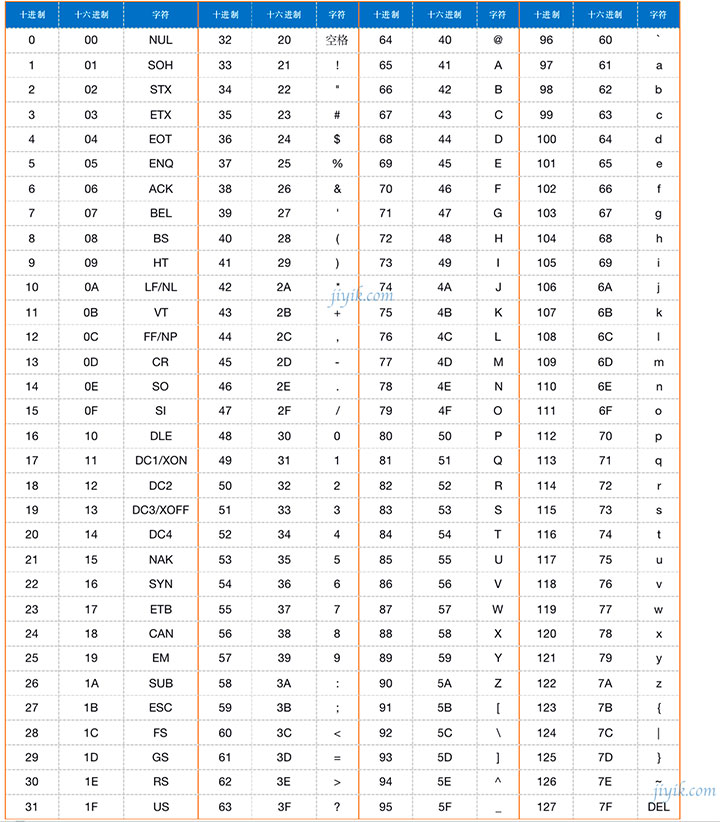
From the above table, we can infer that ASCII values can be represented in the decimal number system from 0 to 127. Let's look at the binary representation of 0 and 127 in an 8-bit byte.
0 is represented by
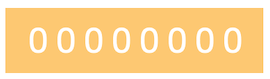
127 is represented by

From the binary representation above, we can infer that the decimal values 0 to 127 can be represented using 7 bits, with the 8th bit being free.
警告From this point on, chaos began.
People came up with different ways to use the remaining eighth bit so that it could represent decimal values from 128 to 255. Then conflicts occurred. For example, Vietnamese used decimal value 182 to represent Vietnamese letters ờ, and Indians used the same value 182 to represent Hindi letters घ. So if an Indian wrote an email containing the letters घ and it was read by Vietnamese, it would be displayed as ờ. Obviously this was not the intended effect.
So how to solve this problem? Next, Unicode comes into play.
Unicode and code points
The Unicode character set maps every character in the world to a unique number. This ensures that there are no conflicts between letters of different languages. These numbers are platform independent.
These unique numbers are called code points in unicode terminology.
Let's see how they are referenced.
Referencing Latin characters using code pointsṍ
U+1E4D
U+ stands for unicode, and 1E4D is the hexadecimal value assigned to the character ṍ.
The English letter A is represented byU+0041
Okay, now that we know this, it’s time to get to the main event.
UTF-8 encoding
Now that we know what unicode is and how every letter in the world is assigned a unique code point, we need a way to represent these code points in computer memory. This is where character encodings come in. The most well-known of these is UTF-8encoding.
UTF-8 encoding is a variable-sized encoding scheme used to represent unicode code points in memory. Variable-sized encoding means that a code point is represented using 1, 2, 3, or 4 bytes depending on its size.
UTF-8 1-byte encoding
The 1-byte coded identifier has the first bit as 0.
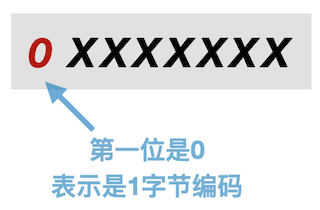
The unicode code point of the English letter A is U+0041. Its binary representation is 1000001.
A is represented in UTF-8 encoding as
The red 0 bit indicates that 1 byte encoding is used, and the remaining bits represent code points
UTF-8 2-byte encoding
ñThe binary value of
the Latin alphabet with code point U+00F1 11110001. This value is larger than the maximum value that can be represented using the 1-byte encoding format, so the alphabet will be represented using the UTF-8 2-byte encoding.
The 2-byte encoding method is identified by the bit sequence 110 of the upper three bits in the first byte and the bit sequence 10 of the upper two bits in the second byte.

The binary value of the Unicode code point U+00F1 is 1111 0001 . Filling these bits with the 2-byte encoding format, we get the UTF-8 2-byte encoding representation of ñ as shown below.
The padding is done starting with the least significant bit of the code point that maps to the least significant bit of the second byte.
The blue binary digits 11110001 represent the binary value of the code point U+00F1, and the red one is the 2-byte encoding identifier. The black zeros are used to fill the empty spaces in the bytes.
UTF-8 3-byte encoding
The Latin character
with code point U+1E4Dṍ is represented using a 3-byte encoding because it is larger than the maximum value that can be represented using a 2-byte encoding.
A 3-byte encoding is identified by the presence of the bit sequence 1110 in the first byte and 10 in the second and third bytes.
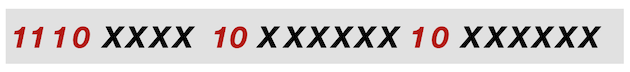
ṍ has a hexadecimal code point of 0x1E4D, and corresponds to a binary value of 1111001001101. Filling these bits into the above encoding format, we get ṍthe UTF-8 3-byte encoding representation of shown below.
The padding is done starting with the least significant bit of the code point that maps to the least significant bit of the third byte.
The red bits represent the 3-byte encoding, the black bits are padding bits, and the blue bits represent the code point.
UTF-8 4-byte encoding
The Unicode code point for the emoji 😭 U+1F62D. This is larger than the maximum value that can be represented using a 3-byte encoding, so it will be represented using a 4-byte encoding.
The 4-byte encoding is identified by 11110 in the first byte followed by 10 in the second, third, and fourth bytes.

The binary representation of U+1F62D is 11111011000101101 . Plugging these bits into the above encoding format gives us the UTF-8 4-byte encoding of 😭 . The least significant bit of the code point maps to the least significant bit of the fourth byte, and so on.
The red bits indicate the 4-byte encoding format, the blue bits are the actual code bits, and the black bits are the padding bits.
We have introduced several encoding methods of UTF-8 in detail above. Next, we will also introduce UTF-16 and UTF-32 encoding methods.
UTF-16 encoding
UTF-16 encoding is a variable-byte encoding scheme that uses either 2 bytes or 4 bytes to represent unicode code points. Most characters in all modern languages are represented using 2 bytes.
The Unicode code point of the Latin letter ñ is U+00F1 , which is represented by 11110001 in binary . Its UTF-16 encoding is
The above representation is in Big Endian byte order mode (MSB first).
UTF-32 encoding
UTF-32 encoding is a fixed-byte encoding scheme that uses 4 bytes to represent all code points.
The English letter A has the Unicode code point U+0041. Its binary representation is 1000001 .
It is represented in UTF-32 encoding as shown below,
The blue bits are the binary representation of the code point. The above representation is in Big Endian byte order mode.
That's all about character sets and character encodings.
For reprinting, please send an email to 1244347461@qq.com for approval. After obtaining the author's consent, kindly include the source as a link.
Related Articles
Encoding an image as Base64 in PHP
Publish Date:2025/04/13 Views:198 Category:PHP
-
There are many ways to encode images into base64 format using several built-in functions in PHP. These functions include: pathinfo file_get_contents base64_encode mime_content_type Encode images to Base64 in PHP using file_get_contents , pa
Base64 encoding pitfalls: ID card number fuzzy query
Publish Date:2025/03/19 Views:73 Category:ALGORITHM
-
First, I will dig out the pits I encountered in the project. In our project, there is such a requirement that the user's ID number cannot be stored in plain text when it is stored in the database. In view of such a requirement, it is natura
使用 JavaScript 编码 HTML
Publish Date:2024/03/20 Views:98 Category:JavaScript
-
本教程将教你如何使用不同的方法对 HTML 字符串进行编码。这些方法的共同点是字符串替换,它替换了具有潜在危险的字符。
JavaScript 邮政编码验证
Publish Date:2024/03/20 Views:97 Category:JavaScript
-
在本文中,我们将学习如何使用正则表达式来验证邮政编码,使用 JavaScript 代码和不同的示例。
在 JavaScript 中编码 HTML 实体的简单解决方案
Publish Date:2024/03/19 Views:173 Category:JavaScript
-
在 JavaScript 中编码 HTML 实体。
Windows PowerShell 中的 Base64 编码
Publish Date:2024/03/04 Views:361 Category:编程语言
-
本文将展示如何编码和解码 base64 字符串。Windows PowerShell 当前版本没有本机命令,因此我们将向你展示如何执行此操作的替代方法。
PowerShell 中的 UTF-8 编码(CHCP 65001)
Publish Date:2024/02/29 Views:322 Category:编程语言
-
本教程将介绍在 PowerShell 中使用 UTF-8 编码的不同方法。
在 C# 中对 Base64 字符串进行编码和解码
Publish Date:2024/01/16 Views:234 Category:编程语言
-
Convert 类可用于在 C# 中将标准字符串编码为 base64 字符串,并将 base64 字符串解码为标准字符串。使用 C# 中的 Convert.ToBase64String() 方法将字符串编码为 Base64 字符串
C++ 中的 Base 64 编码实现
Publish Date:2023/08/25 Views:208 Category:C++
-
本文将讨论 C++ 中的 base_64 编码。首先,我们将讨论 base_64 编码以及需要它的原因和位置。 稍后,我们将讨论 C++ 中的 base_64 编码/解码。

